open all section menu
close all section menu
- + Preface
- + Chapter1 Resource Management and Registry
- + Chapter2 Resource management before JNIC and JPNIC
- + Chapter3 Restructuring toward fully-fledged resource management by JPNIC
- + Chapter4 Transition of resource management policy for domain names
- + Chapter5 IP address policy in the fully-fledged Internet age
- + Chapter6 Building the global IP address management structure
- + Chapter7 Framework for global domain name management led by ICANN
- + Chapter8 General-use JP Domain Name and establishment of JPRS
- + Chapter9 “Publication” and “disclosure” of registration information
- + Chapter10 IPv4 address pool exhaustion and IPv6
- + Appendix1: IP address and domain name
- + Appendix2: Transition of Internet resource management
- + About History Compilation Team
- + Revision history


Chapter5 IP address policy in the fully-fledged Internet age
Because of the explosive expansion of the Internet after the 1990s, IP address use and routing technology required significant reforms, which led to a drastic change of IP address management policy.
IP address management before the commercial Internet
The Internet of the 1980s was a research network mainly used in the U.S. Its scale was extremely small compared with the Internet as we now know it, and it was used only for things such as joint operation of super computers, information sharing and other exchange among researchers.
In the beginning, Internet protocol (IP) related parameters were managed personally by Jon Postel of the University of Southern California. With the gradual increase in the number of Internet users, Postel looked to his colleagues for additional management support, and this loose arrangement came to be called the Internet Assigned Number Authority (IANA). At that time, there was only a simple rule that said “if you need protocol parameters, you should contact Postel.”[93]
IPv4 addresses in those days were divided into three types: Class A, B and C, indicated by the value of the leading 4 bits. Each class was designated a different size of “network address” to be assigned to connected networks: Class A contained 24-bit network addresses (able to hold approximately 17 million hosts), Class B addresses were 16-bit (able to hold approximately 66,000 hosts), and Class C addresses were 8-bit (able to hold 254 hosts)[94]. These addresses were called “classful addresses,” and the unit of routing was automatically identified by the value of the leading 4 bits.
In the beginning, the number of computers that needed to be connected was small, and there seemed little prospect of a significant increase in the number. Therefore, IP addresses were assigned fairly liberally, in such a way that Postel assigned Class A addresses with huge address space capable of holding about 17 million hosts to large businesses and universities.
Column: Routing
The basic function of all kinds of networks including the Internet is to transfer data among the various users or pieces of equipment connected to the network. To achieve this function, each device connected to the network should know, at the time of transferring data to a certain destination, to which connected line or adjacent device it is going to send the data. As such, checking up paths from the next forwarding destination to final destination and choosing the best path is called “routing.”
On the Internet, data is processed in the form of packets, and information about the forwarding destination is stored in all packets as an IP address. A TCP/IP device maintains a “routing table” that lists the routes from one forwarding destination to another, all of which are specified by a particular IP address assigned to each device.
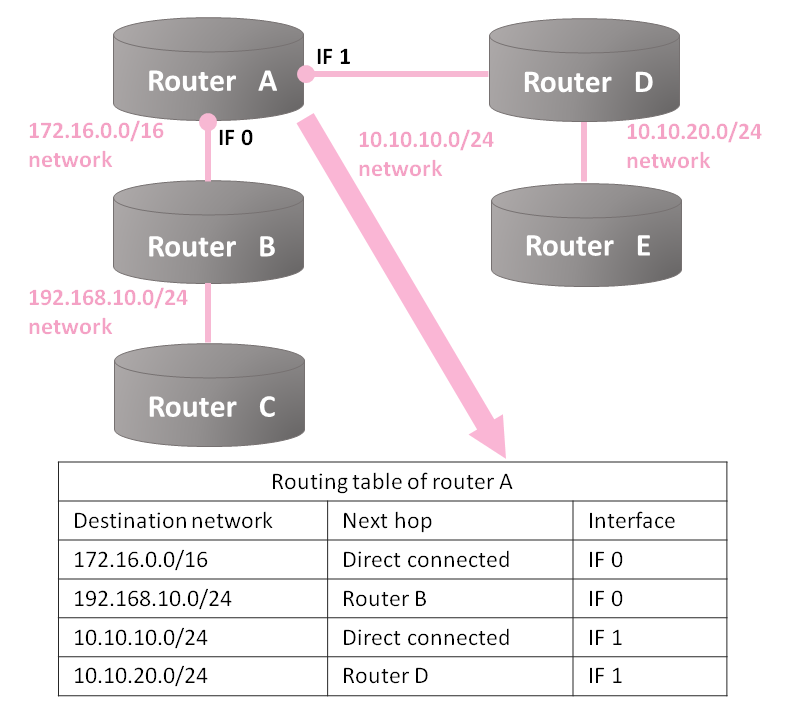
The diagram above shows a simple configuration containing four networks connected with five routers and a routing table storing four entries. When a network is added, one entry is added to routing tables in all routers. A small and simple network like this often functions without problem, by specifying the next forwarding destinations for all the existing networks in advance. Adding information on the next destination for all networks into a routing table of every router as mentioned above is called static routing.
However, if a network becomes very large, it becomes substantially more difficult to change its settings each time a new network is added. In many cases, therefore, routing is carried out by activating the routing protocol on a router and letting the router automatically exchange routing information with adjacent routers. This is called dynamic routing. The act of communicating routing information to adjacent routers using the routing protocol is called a route advertisement or simply advertisement.
As new networks are persistently added to the Internet, so too the routing table of the Internet persistently grows. Since CIDR was introduced, the Internet has been operated with hierarchical routing. In hierarchical routing, an Autonomous System (AS) – which corresponds in general to an ISP – is considered a unit, and routing between ASes and routing within an AS are separated. The number of routing table entries shared among ASes that conduct inter-AS routing was about 500,000 at the time of writing, about five times the 100,000 routes back in 2001 and twice the 250,000 routes in 2008[95]. A rise in the number of routing table entries forces not only an increase in router memory capacity but also enhanced CPU capacity for computing all the changes happening in each route. For these reasons, routing scalability has been a persistent issue since the early days.
- Reference: Internet terms in ten minutes: Routing (in Japanese)
- https://www.nic.ad.jp/ja/newsletter/No38/0800.html
Two concerns regarding the commercial Internet
Commercial Internet service providers appeared in the U.S. around 1990[96], and Internet access became available to general users for a fee. With this move, the Internet started to be used widely by the general public, moving beyond its research and academic origins. Accordingly, the Internet – and the number of Internet users – began to expand exponentially.
Directly after the appearance of commercial providers, the following issues became a concern among relevant parties all over the world[97]:
- Finite nature of IPv4 addresses – Exhaustion of available address pool might occur in the near future.
- Limitation of routing mechanism – When the total number of routes exceeds the number that the Internet as a whole can handle, the routing mechanism might break down.
To address these concerns, the IETF established the Routing and Addressing (ROAD) Group in 1991[98] and started to work on countermeasures.
IPv6 as next-generation Internet protocol
One radical approach to countering the finite nature of the IPv4 address pool was to develop a next-generation IP (Internet protocol) in anticipation of IPv4 exhaustion. The ROAD Group had investigated some protocols as candidates for the next-generation IP, and the IAB made a proposal for the use of a protocol based on the Connection-Less Network Protocol (CLNP), defined by ISO for the next-generation IP, as IP version 7 in June 1992[99][100]. However, the IETF could not go along with the proposal and denied it. Taking that incident as a trigger, the IETF established the IPng (Internet Protocol Next Generation) Working Group and started a full-scale study of the next-generation IP. Additional protocol candidates were suggested, some candidates were integrated, and active discussions were held. As a result, a protocol called Simple IP Plus (SIPP) was adopted as the next-generation IP in 1994. After that, the detailed parts were discussed, and the basic specification of IP version 6 (IPv6) based on SIPP was published as RFC 1883[101] in December 1995[102].
Predictions were also made as to when the pool of available IPv4 addresses would exhaust. The Address Lifetime Expectation (ALE) Working Group[103] of the IETF concluded in July 1995 that the pool would be depleted in “2013±eight years.” This prediction was right with regard to exhaustion of the IANA global address pool (February 2011)[104] followed by APNIC (April 2011)[105], RIPE NCC (September 2012)[106] and LACNIC (June 2014)[107] that had already occurred at the time of writing this document[108].
Coming of CIDR age
As mid-term measures to cope with the finite nature of IPv4 addresses, amendment of the IPv4 address distribution procedure was promoted, together with measures relating to the routing mechanism.
The size of the networks connected to the Internet varied widely. When using classful addresses as mentioned at the beginning of this chapter, even the 8-bit space of a Class C address (capable of holding 254 hosts) was too big for a small organization, and there was almost no connected organization that required the 24-bit space of a Class A address (capable of holding approximately 17 million hosts). Therefore, it was obvious that the address usage scheme was inefficient. Furthermore, when the number of new organizations connecting to the Internet increased rapidly, the number of routes increased rapidly too, resulting in a burden for the routing mechanism. So the breakdown of the routing itself became another practical concern. To mitigate the increase in the number of routes, Class B addresses were assigned to organizations requiring several Class C addresses, thereby giving priority to route aggregation over effective usage of available address space.
The eventual solution to this challenge was so-called “classless” routing. This technology enables routing protocols to carry the prefix length (the size of the routing unit) as routing information, as well as the IP addresses.
Column: IP address notation based on CIDR
As described earlier, before the appearance of classless routing technology, network addresses were classified into Class A, B or C as the units of routing. However a technique called subnetting allowed those classful units to be segmented into smaller, “subnetted” network addresses. This was achieved by using a network mask set at the interface of a router or host, so that routing was carried out on the basis that other subnets in the network address were all divided by the subnet mask.
In the classless technology, it is possible to define a unit of routing with an arbitrary size using the routing protocol. The following notation became standard to show the unit of routing, together with IP address:
[IP address]/[prefix length]
(/ is pronounced as “slash”)
In the context of IP addresses, prefix refers to “the leading part of an IP address.” A prefix identifies an individual routing unit, so it can be considered as the classless version of “network address.” A prefix length shows the length of the prefix by the number of bits. For instance, a Class C address uses the leading 24 bits as the “network address.” Accordingly, the Class C address block “202.12.30.0—202.12.30.255” used for JPNIC's public server is written as “202.12.30.0/24.” The “.0” at the right end is often omitted, so the address is often represented as “202.12.30/24.” For a Class A address block (which has a shorter prefix), addresses take a shorter form such as “10/8” (indicating 10.0.0.0—10.255.255.255).
Slash notation can also be used to indicate the size of an IP address block without showing the specific unit of routing; for example, /24 (slash 24: size equivalent to a Class C) or /22 (size equivalent to four Class Cs) can be used without specifying the IP address.
This way of writing is named “Prefix Notation” (see RFC 4632)[109].
Classless technology enabled ISPs to summarize multiple separate pieces of routing information from their connected networks into a single public route, so that the routing information could be advertised to other ISPs in bulk. This is called route aggregation. For instance, if one ISP has the address block ranging from 192.168.0.0 to 192.168.255.255 and advertises it in a classful way without aggregation, 256 Class C addresses are advertised. On the contrary, if the ISP adopts classless technology, 256 /24 blocks are summarized into one lump, and a single piece of routing information noting 192.168.0.0/16 is advertised. In this way the amount of routing information to be advertised among ISPs can be reduced significantly, and the burden on the Internet as a whole can be lessened. Routing in units of ISP aggregations with classless technology is called Classless Inter-Domain Routing (CIDR). CIDR was standardized in RFC 1518[110] in September 1993.
In CIDR, it is necessary to distribute consecutive IP addresses to an ISP to enable aggregation. JPNIC addressed that need immediately and in November 1993, shortly after the publication of RFC 1518, it started distributing (allocating) consecutive IP addresses to JPNIC members, so that the addresses could be re-distributed (assigned) to the organizations connected to those members[111]. It was September 1995 when ISPs in Japan really started to aggregate routing information utilizing CIDR[112]. The graph shown below (Fig. 5-1) indicates the amount of routing information advertised within Japan before and after the Japanese ISPs started routing aggregation with CIDR. It shows that aggregation contributed greatly to the reduction in the amount of routing information.

With CIDR, a new concept of hierarchical routing was introduced to the Internet. Before CIDR, IP addresses were assigned without considering how they related to other networks, and networks had freedom to choose the party to which they connected. However, since the introduction of CIDR, IP addresses are basically assigned from the address block of the ISP that provides connectivity, meaning that a change in ISP requires a change in addressing. In other words, while CIDR brought scalability to the Internet, it came at the cost of some flexibility.
Economical use of IPv4 addresses with classless technology
Classless technology enabled address assignments in units smaller than a Class C address, and JPNIC started making sub-Class C assignments in September 1995[113]. This made it possible to assign address spaces of an appropriate size, economically, to organizations ranging from very small groups to large-scale enterprises for which one Class C address was not sufficient.
As described above, CIDR technology is now indispensable for the economical usage of IPv4 addresses. However, it did not come about simply through routing aggregation by ISPs and block allocation by registries.
To start assigning in units smaller than a Class C address, the issue of setting reverse name servers had to be addressed. In the case of classful addressing, the PTR record (a DNS resource record used for reverse lookup) could be configured by just following the basic condition under which d.c.b.a.in-addr.arpa corresponded to the IP address of a.b.c.d. However, when IP addresses are assigned in units smaller than a Class C address, c.b.a.in-addr.arpa would be shared by multiple different organizations. To handle this, JPNIC published a document[114] at the start of the assignment and described an applicable configuration method for reverse names using CNAME record (a DNS resource record for specifying that the domain name is an alias of another, canonical domain name). Moreover, the subnet mask with the values of all zeros or all ones (all-0 subnet, all-1 subnet) could not be used on some hosts that followed the old implementation. This made it necessary to check the software of the hosts on the concerned network before starting such subnetting37.
The purpose of CIDR addressing was not only to aggregate multiple Class C addresses, but to also allow the allocation of Class A addresses with the same subnetting technique. RFC 1797 “Class A Subnet Experiment”[115] issued in April 1995, singled out 39/8 (a Class A address) and made it available for experimental usage. The RFC specified that all ASes could use /24 addresses from that block by representing the value of the AS number in the second and third octets. At the end of the experiment it was confirmed that there were no major problems in such usage. After that, IANA started to allocate /8 addresses out of the Class A pool to RIRs in 1996, and each RIR began allocating the addresses to LIRs as a pilot project[116].
In this way, the technical community of the Internet had responded to the rapidly increasing demand for the Internet in terms of routing technology and IP address distribution, gaining the cooperation of ISPs and end users.
| << Chapter4 | Ver.1.0-April 2015 | Chapter6 >> |
[93] “If you are
developing a protocol or application that will require the
use of a link, socket, port, protocol, or network number
please contact Jon to receive a number assignment.”
J. Postel, J. Vernon, “ASSIGNED NUMBERS”, RFC 820, January
1983
https://tools.ietf.org/html/rfc820
[94] The concept of
class was introduced to IPv4 address for the first time
in RFC 791.
“INTENRET PROTOCOL DARPA INTERNET PROGRAM PROTOCOL
SPECIFICATION”, RFC 719, September 1981
https://tools.ietf.org/html/rfc791
[95] BGP Routing Table
Analysis Reports
http://bgp.potaroo.net/
[96] FYI32, R. Zakon,
“Hobbes' Internet Timeline”, RFC 2235, November 1997, p9
http://tools.ietf.org/html/rfc2235
[97] Chiappa, N.,
“The IP Addressing Issue”
http://tools.ietf.org/html/draft-chiappa-ipaddressing-00
[98] P. Gross, P. Almquist,
“IESG Deliberations on Routing and Addressing”, RFC 1380,
November 1992
http://tools.ietf.org/html/rfc1380
[99] Internet Architecture
Board, Internet Draft “IP Version 7”, July 1992
http://wiki.tools.ietf.org/html/draft-iab-ipversion7-00
[100] Chapin, L.,
“A summary of the IAB's proposals in response to the work
of the ROAD group” , July 1992
http://rms46.vlsm.org/3/0001.txt
[101] S. Deering,
R. Hinden, “Internet Protocol, Version 6 (IPv6)
Specification”,
RFC 1883, December 1995
http://tools.ietf.org/html/rfc1883
[102] Hinden, R.
“IPv6 Past, Present, and Future”, 2012
http://go6.si/wp-content/uploads/2012/10/BobHinden_IPv6_Past_Present_Future-01.pptx.pdf
[103] Address Lifetime
Expectations Working Group (ALE)
http://www.ietf.org/wg/concluded/ale.html
[104] IPv4 address
stock exhaustion at IANA and address allocation by
JPNIC in the future
https://www.nic.ad.jp/ja/topics/2011/20110204-01.html
[105] Notice of
IPv4 address stock exhaustion at APNIC, and announcement
of address management policy to be applied by JPNIC
after exhaustion
https://www.nic.ad.jp/ja/topics/2011/20110415-01.html
[106] [News
bulletin] IPv4 address exhausted at the European
Regional Internet Registry
https://www.nic.ad.jp/ja/topics/2012/20120918-01.html
[107] IPv4 address
stock exhaustion at the Regional Internet Registry for Latin
American and the Caribbean region
https://www.nic.ad.jp/ja/topics/2014/20140612-01.html
[108] Akira Kato, Status of addresses and routing (November issue, 1995), IP Meeting ’95 proceedings, November 1995
[109] Li, T., Fuller,
V., RFC4632”Classless Inter-domain Routing (CIDR):The
Internet Address Assignment and Aggregation Plan”,
August 2006
http://tools.ietf.org/html/rfc4632
[110] RFC1518 “An
Architecture for IP Address Allocation with CIDR”
http://tools.ietf.org/html/rfc1518
[111] Toshiya Asaba, A assignment of IP addresses, IP Meeting '95 Proceedings, November 1995
[112] Akira Kato, Status of addresses and routing (November issue, 1995), IP Meeting '95 Proceedings, November 1995
[113] Pilot
Project to assign address spaces smaller than Class
C (sub-allocation)
https://www.nic.ad.jp/doc/jpnic-00022.html
[114] Configuration
of DNS reverse lookup for assignments of addresses
smaller than /24
https://www.nic.ad.jp/doc/jpnic-00880.html
[115] IANA, “Class A
Subnet Experiment”, RFC 1797, April 1995
http://tools.ietf.org/html/rfc1797
[116] Akinori Maemura, Status of assignment of former Class A addresses, IP Meeting '97 Proceedings, December 1997