

MDN ライブラリ
機能概要
MDN ライブラリ (libmdn, libmdnlite) は多言語ドメイン名の変換に関わる 各種の処理を実装するモジュールの集合です。 これらのライブラリは以下の機能を提供します。
- エンコーディング (コードセット) 変換
- NAMEPREPに基づく文字列の正規化
- DNS メッセージの解析、再組み立て
- クライアント用設定ファイルの読み込み
ただし、libmdn はすべての機能を実装していますが、 libmdnlite は「エンコーディング (コードセット) 変換」の機能が一部省略 されています。 省略されている機能について詳しくは、 エンコーディング (コードセット) 変換 を参照して下さい。 省略されていない機能についての使用方法は、libmdn とまったく変わりません。
特に断らない限り、本ドキュメントの記述は、libmdn, libmdnlite 双方に 共通のものとします。
エンコーディング (コードセット) 変換
文字列のエンコーディングを変換し、その結果を返します。 MDN ライブラリの内部では、文字列はすべて UTF-8 エンコーディングであるとして 取り扱われます。そこで、このモジュールは以下の機能を提供します。
- あるエンコーディングから UTF-8 への変換
- UTF-8 からあるエンコーディングへの変換
エンコーディングは大きく分けて、次の2種類があります。
- アプリケーションが使用するエンコーディング方式 (シフトJIS、EUC 等)
- 多言語ドメイン名で使用するために設計された特別なエンコーディング方式 (Punycode, RACE等)
このうち、libmdn は両方のエンコーディング方式に対応していますが、 libmdnlite は後者のエンコーディング方式にだけ対応しています。
前者のエンコーディング変換のために、libmdn では iconv()
関数を使用しています。
言い換えれば、前者のエンコーディング変換に対応していない libmdnlite
では、iconv() を使用しません。
後者のエンコーディング変換のために、libmdn および libmdnlite では 独自の変換関数を実装して使用しています。
NAMEPREP に基づく正規化
NAMEPREP の記述に従って、与えられたドメイン名文字列の正規化、文字の マッピング、禁止文字の検査、文字が割り当てられていないコードポイント を含んでいるかどうかの検査を行います。
ローカルルールによるドメイン名のマッピング
NAMEPREP とは別に、ローカルルールに基づいて文字のマッピングを行います。
DNS メッセージの解析、再組み立て
DNS プロキシサーバ (mdnsproxy) では、クライアントから送られてきた DNS メッセージに含まれるドメイン名に対してエンコーディング変換や正規化を行い、 その結果を DNS サーバに送ります。このために以下の機能を提供します。
- DNSメッセージを解析し、ドメイン名を取り出す
- 変換したドメイン名を用いてDNSメッセージを再構成する
ローカルエンコーディングの判別
アプリケーションプログラムが使用しているローカルエンコーディング (コードセット) を自動判別します。判別は基本的にはアプリケーションの ロケール情報を利用しますが、環境変数で指定することも可能になっています。
クライアント用設定ファイルの読み込み
MDN ライブラリをリンクしたアプリケーションでエンコーディング 変換や正規化を行う場合、使用するエンコーディングや正規化方式は 設定ファイルに記述します。このファイルを読み込む機能を提供します。
モジュール一覧
MDN ライブラリは以下のモジュールから構成されます。
-
aceモジュール - amcacez や race といった、ドメイン名のエンコーディング変換モジュール で共通する処理をまとめたモジュール
-
altdudeモジュール - ドメイン名のエンコーディング方式の一つとして提案された AltDUDE エンコーディングの変換モジュール
-
amcacemモジュール - ドメイン名のエンコーディング方式の一つとして提案された AMC-ACE-M エンコーディングの変換モジュール
-
amcaceoモジュール - ドメイン名のエンコーディング方式の一つとして提案された AMC-ACE-O エンコーディングの変換モジュール
-
amcacerモジュール - ドメイン名のエンコーディング方式の一つとして提案された AMC-ACE-R エンコーディングの変換モジュール
-
amcacevモジュール - ドメイン名のエンコーディング方式の一つとして提案された AMC-ACE-V エンコーディングの変換モジュール
-
amcacewモジュール - ドメイン名のエンコーディング方式の一つとして提案された AMC-ACE-W エンコーディングの変換モジュール
-
amcacezモジュール - ドメイン名のエンコーディング方式の一つとして提案された Punycode (旧称 AMC-ACE-Z) エンコーディングの変換モジュール
-
apiモジュール - アプリケーション向けに、ドメイン名の エンコーディング変換や正規化を行うための高レベルのインタフェースを提供 するモジュール
-
braceモジュール - ドメイン名のエンコーディング方式の一つとして提案された BRACE エンコーディングの変換モジュール
-
checkerモジュール - ドメイン名に使用できない文字が含まれているかどうかを検査する モジュール
-
converterモジュール - 文字列のエンコーディング(コードセット)の変換モジュール
-
debugモジュール - デバッグ用出力のためのユーティリティモジュール
-
delimitermapモジュール - ドメイン名の中の特定の文字をピリオド (`
.') に マッピングするためのモジュール -
dnモジュール - DNS メッセージ内のドメイン名の展開・圧縮を行うモジュール
-
dudeモジュール - ドメイン名のエンコーディング方式の一つとして提案された DUDE エンコーディングの変換モジュール
-
filecheckerモジュール - ドメイン名に使用できない文字を定義したファイルを読み込んで、与えられた 文字列に使用できない文字が含まれているかどうかを調べるモジュール
-
filemapperモジュール - 文字のマッピング規則を定義したファイルを読み込んで、ドメイン名文字列中 の文字のマッピングを行うモジュール
-
laceモジュール - ドメイン名のエンコーディング方式の一つとして提案された LACE エンコーディングの変換モジュール
-
localencodingモジュール - アプリケーションの使用しているエンコーディングを推測するモジュール
-
logモジュール - MDN ライブラリのログの出力処理を制御するモジュール
-
maceモジュール - ドメイン名のエンコーディング方式の一つとして提案された MACE エンコーディングの変換モジュール
-
mapperモジュール - ドメイン名中の文字のマッピングを行うためのモジュールです。
-
mapselectorモジュール - 与えられたドメイン名のトップレベルのドメインに応じて、異なるロー カルなマッピングを行うモジュール
-
msgheaderモジュール - DNS メッセージのヘッダの解析モジュール
-
msgtransモジュール - DNS プロキシサーバでの DNS メッセージの変換を行うためのモジュール
-
nameprepモジュール - NAMEPREP に記述された、ドメインの正規化、マッピング、禁止文字の検査など を行うモジュール
-
normalizerモジュール - 文字列の正規化を行うモジュール
-
raceモジュール - ドメイン名のエンコーディング方式の一つとして提案された RACE エンコーディングの変換モジュール
-
resモジュール - アプリケーションでドメイン名の エンコーディング変換や正規化を行うための低レベルのインタフェースを 提供するモジュール
-
resconfモジュール - アプリケーションでドメイン名の エンコーディング変換や正規化を行う際の設定ファイルを読み込むためのモジュール
-
resultモジュール - ライブラリの各関数が返すリザルトコードを扱うモジュール
-
selectiveencodeモジュール - テキストの中から非ASCII文字を含むドメイン名を探し出すモジュール
-
strhashモジュール - 文字列をキーとするハッシュ表を実現するモジュール
-
ucsmapモジュール - 文字のマッピング規則の登録、およびマッピングを行うモジュール
-
ucssetモジュール - 文字の登録を行うモジュール
-
unicodeモジュール - Unicode の各種文字属性を取得するモジュール
-
unormalizeモジュール - Unicode で定義されている標準の正規化を行うモジュール
-
utf5モジュール - ドメイン名のエンコーディング方式の一つとして提案された UTF-5 の基本処理を行うモジュール
-
utf6モジュール - ドメイン名のエンコーディング方式の一つとして提案された UTF-6 エンコーディングの変換モジュール
-
utf8モジュール - UTF-8 エンコーディング文字列の基本処理を行うモジュール
-
utilモジュール - 他のモジュールで使われる共用関数を提供するモジュール
-
versionモジュール - ライブラリのバージョン情報を取得するためのモジュール
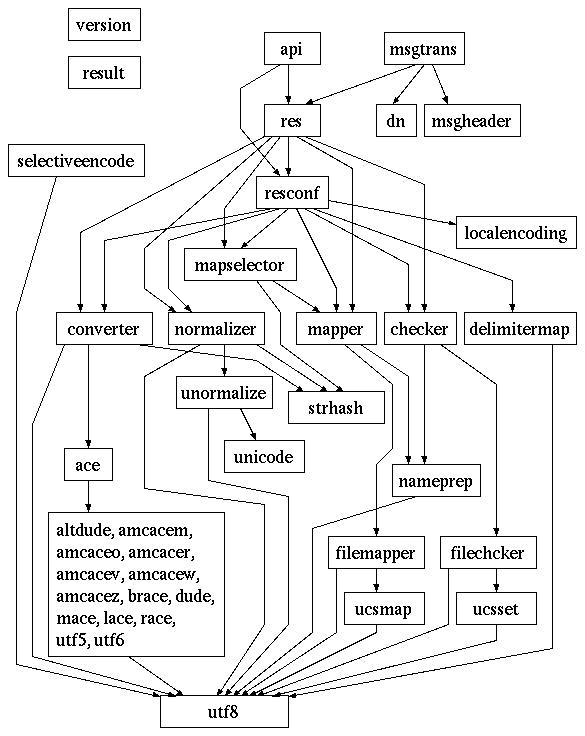
以下にモジュールの呼び出し関係図を示します。ただしほとんどすべての
モジュールから呼び出されている debugモジュールと
logモジュール、また共用関数を納めた
utilモジュールは割愛してあります。
既に廃れたエンコーディング方式
モジュール一覧を見て分かる通り、 MDN ライブラリには多言語ドメイン名用に提案された数多くの エンコーディング方式が実装されています。
しかしながら、mDNkit では、エンコーディング方式の多くを既に廃れたもの
という扱いにしています。
廃れたエンコーディングは、mDNkit を普通のインストール手順でコンパイル
しても使用できないようになっています。
使用するには、インストール時に configure の
--enable-extra-ace オプションを指定する必要があります。
また、将来の MDNライブラリでは、これらのエンコーディング方式がサポート
されなくなる可能性もあります。
この点は十分にご留意下さい。
各エンコーディング方式の位置付けは次の通りです。
- 普通にサポートされているエンコーディング方式
- Punycode (旧称 AMC-ACE-Z), DUDE, RACE
- 既に廃れたエンコーディング方式
- AltDUDE, AMC-ACE-M, AMC-ACE-O, AMC-ACE-R, AMC-ACE-W, AMC-ACE-V, BRACE, LACE, MACE, UTF-5, UTF-6
モジュール詳細
MDN ライブラリに含まれるすべてのモジュールについて、その仕様を記述 します。 まず各モジュールで共通に使用される、関数の戻り値について説明したあと、 モジュール毎に詳細を解説します。
API関数の戻り値
MDNライブラリのほとんど全てのAPI関数は、戻り値として列挙型である
mdn_result_t 型の値を返します。値の一覧とその意味を示します。
-
mdn_success - 処理が成功したことを示します。
-
mdn_notfound - 検索処理などにおいて、見つからなかったことを示します。
-
mdn_invalid_encoding - エンコーディング変換において、入力された文字列のエンコーディングが 間違っていることを示します。
-
mdn_invalid_syntax - ファイルなどの書式に間違いがあることを示します。
-
mdn_invalid_name - 指定された名前が間違っていることを示します。
-
mdn_invalid_message - 入力されたDNSメッセージが正しくないことを示します。
-
mdn_invalid_action - 文字列の変換方法の指定に誤りがあることを示します。
-
mdn_invalid_codepoint - 入力された文字のコードポイントが、規定範囲外の値であることを示します。
-
mdn_buffer_overflow - 結果を格納するバッファの大きさが足りないことを示します。
-
mdn_noentry - 指定された項目が存在しないことを示します。
-
mdn_nomemory - メモリのアロケーションに失敗したことを示します。
-
mdn_nofile - 指定されたファイルの読み込みに失敗したことを示します。
-
mdn_nomapping - 文字列のエンコーディング(コードセット)を変換する際、 変換ターゲットの文字集合に含まれない文字があった (つまり 正しく変換できなかった) ことを示します。
-
mdn_context_required - 文字の大文字小文字変換の際に、正しい変換を行うには文脈情報が 必要であることを示します。
-
mdn_prohibited - 入力された文字列が、使用を禁止する文字を含んでいたことを示します。
-
mdn_failure - 上記のいずれにも当てはまらないエラーが発生したことを示します。
aceモジュール
aceモジュールは、amcacez,
race といった、ドメイン名の
エンコーディング変換モジュールで共通する処理をまとめたモジュールです。
このモジュールは、converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
Punycode や RACE といったエンコーディングとの
変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__ace_convert
mdn_result_t
mdn__ace_convert(mdn__ace_t ctx, mdn_converter_dir_t dir,
const char *from, char *to, size_t tolen)
ACE文字列とUTF-8文字列の相互変換を行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uならACEからUTF-8へ、
mdn_converter_u2lならUTF-8からACEへの変換となります。
ctx の型 mdn__ace_t は次のように定義されており、
ACE のプリフィックス・サフィックスや実際の変換関数へのポインタを
保持しています。
enum { mdn__ace_prefix, mdn__ace_suffix };
typedef mdn_result_t
(*mdn__ace_proc_t)(const char *from, size_t fromlen,
char *to, size_t tolen);
typedef struct {
int id_type; /* mdn__ace_prefix/mdn__ace_suffix */
const char *id_str; /* prefix/suffix string */
mdn__ace_proc_t encoder;/* encode procedure */
mdn__ace_proc_t decoder;/* decode procedure */
} mdn__ace_t;
dir が mdn_converter_l2u の場合には次のような
処理が行われます。
- from で指定されるドメイン名文字列をラベルに分解し、それぞれに ついて以下の 2 から 5 の処理を実行します。
- ctx で指定されるデータから ACE のプリフィックスあるいは サフィックスを取り出し、ラベル文字列がそれにマッチするかを調べます。 マッチしなければ変換せずにそのままコピーします。
- マッチすればラベルからプリフィックスあるいはサフィックスを除去し、 ctx で指定されるデコード関数を呼び出して UTF-8 エンコーディングの ラベル文字列に変換します。
- デコード結果が従来の ASCII ドメイン名として正当なものかどうかを調べます。 もし正当なものなら、そのラベルは本来 ACE に変換してはならないものなので エラーとします。
- デコードした文字列をctx で指定されるエンコード関数を呼び出して 再度 ACE に戻します。これと元の ACE 文字列を比較し、マッチしなければ エラーとします。
- ラベル毎の変換結果をドメイン名にまとめて to で指定される 領域に格納します。
また dir が mdn_converter_u2l の場合には次のような
処理が行われます。
- from で指定されるドメイン名文字列をラベルに分解し、それぞれに ついて以下の 2 から 4 の処理を実行します。
- ラベル文字列が従来の ASCII ドメイン名として正当なものかどうかを調べます。 正当なものであれば ACE への変換は不要なのでそのままコピーします。
- ctx で指定されるエンコード関数を呼び出して ACE に変換します。
- ctx で指定されるデータから ACE のプリフィックスあるいは サフィックスを取り出し、ACE 変換結果の文字列に付加します。
- ラベル毎の変換結果をドメイン名にまとめて to で指定される 領域に格納します。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
altdudeモジュール
altdudeモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AltDUDE エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AltDUDE エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__altdude_open
mdn_result_t
mdn__altdude_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AltDUDEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__altdude_close
mdn_result_t
mdn__altdude_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AltDUDEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__altdude_convert
mdn_result_t
mdn__altdude_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AltDUDEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AltDUDEエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングからAltDUDE
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcacemモジュール
amcacemモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AMC-ACE-M エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AMC-ACE-M エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcacem_open
mdn_result_t
mdn__amcacem_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AMC-ACE-Mエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacem_close
mdn_result_t
mdn__amcacem_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AMC-ACE-Mエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacem_convert
mdn_result_t
mdn__amcacem_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AMC-ACE-Mエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AMC-ACE-MエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから AMC-ACE-M
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcaceoモジュール
amcaceoモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AMC-ACE-O エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AMC-ACE-O エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcaceo_open
mdn_result_t
mdn__amcaceo_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AMC-ACE-Oエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcaceo_close
mdn_result_t
mdn__amcaceo_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AMC-ACE-Oエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcaceo_convert
mdn_result_t
mdn__amcaceo_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AMC-ACE-Oエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AMC-ACE-OエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから AMC-ACE-O
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcacerモジュール
amcacerモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AMC-ACE-R エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AMC-ACE-R エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcacer_open
mdn_result_t
mdn__amcacer_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AMC-ACE-Rエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacer_close
mdn_result_t
mdn__amcacer_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AMC-ACE-Rエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacer_convert
mdn_result_t
mdn__amcacer_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AMC-ACE-Rエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AMC-ACE-RエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから AMC-ACE-R
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcacevモジュール
amcacevモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AMC-ACE-V エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AMC-ACE-V エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcacev_open
mdn_result_t
mdn__amcacev_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AMC-ACE-Vエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacev_close
mdn_result_t
mdn__amcacev_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AMC-ACE-Vエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacev_convert
mdn_result_t
mdn__amcacev_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AMC-ACE-Vエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AMC-ACE-VエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから AMC-ACE-V
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcacewモジュール
amcacewモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
AMC-ACE-W エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
AMC-ACE-W エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcacew_open
mdn_result_t
mdn__amcacew_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
AMC-ACE-Wエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacew_close
mdn_result_t
mdn__amcacew_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
AMC-ACE-Wエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacew_convert
mdn_result_t
mdn__amcacew_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
AMC-ACE-Wエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
AMC-ACE-WエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから AMC-ACE-W
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
amcacezモジュール
amcacezモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
Punycode
エンコーディング (旧称 AMC-ACE-Z) とUTF-8との間の変換を行うモジュールです。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
Punycode エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__amcacez_open
mdn_result_t
mdn__amcacez_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Punycodeエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacez_close
mdn_result_t
mdn__amcacez_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Punycodeエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__amcacez_convert
mdn_result_t
mdn__amcacez_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Punycodeエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
PunycodeエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから Punycode
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
apiモジュール
apiモジュールは、アプリケーション向けに、
ドメイン名のエンコーディング変換や正規化を行うための高レベルの
インタフェースを提供するモジュールです。
一般のアプリケーションはこのモジュールを使用することで、多言語ドメインに
関する一連の処理を容易に行うことができるように設計されています。
このモジュールでは対応できない特殊な処理を行いたいときは、
より低レベルなインターフェースを提供する
resモジュールを使用します。
なお、
環境変数 MDN_DISABLE
が設定されている場合は、以下に挙げられた文字列変換用の関数を使用しても
文字列の変換は行われず、元の文字列のままの結果が返されます。
MDN_DISABLE が設定されている環境で文字列の変換を強制的に行う場合や、
アプリケーションでこれらの API 関数を使用するうえで
MDN_DISABLE の設定に関係なく一定の動作を保証したい場合は、
mdn_enable
を事前に使用しておかなければなりません。
以下にモジュールの提供するAPI関数を示します。
mdn_enable
void mdn_enable(int on_off);
通常、 環境変数 MDN_DISABLE が宣言されている場合、ドメイン名変換処理は 行なわれず、元の文字列のままの結果が返されますが、 この関数はその設定をオーバーライドすることができます。
MDN_DISABLE が設定されているかどうかにかかわらず、 on_off に 0 以外の値を指定してこの関数を使用すると、 それ以降はドメイン名の変換を行うようになります。 0 を指定すると、それとは逆にドメイン名の変換を行わず、 元の文字列のままの結果を返すようになります。
mdn_nameinit
mdn_result_t mdn_nameinit(void);
ライブラリ全体の初期化を行い、あらかじめ決められたファイル
(mdn.conf)
から設定を読み込みます。ただし、二度以上この関数を呼んでも、初期化が行わ
れるのは最初の呼び出し時だけです。
この関数を呼び出す前に、後述する mdn_encodename、あるいは
mdn_decodename が呼び出されたときは、エンコード、デコード
の処理に先だって自動的に初期化が行われます。
返される値は
mdn_success、
mdn_nofile、
mdn_invalid_syntax、
mdn_invalid_name、
mdn_nomemory
のいずれかです。
mdn_encodename
mdn_result_t mdn_encodename(int actions, const char *from, char *to, size_t tolen);
ドメイン名のエンコードを行います。 入力文字列 from を変換し、結果を to と tolen で指定される領域に書き込みます。
actions には、mdn_encodenameに行わせたいエンコード
動作を指定します。次に挙げるフラグの論理和の値
(例: MDN_NAMEPREP | MDN_IDNCONV) を指定するようにします。
指定された動作は、ここに挙げた順序でそれぞれ行われます。
-
MDN_LOCALCONV - ローカルエンコーディング (shift_JIS や Big5 など) の文字列を UTF-8 に変換する。(libmdn でだけ使用できます。libmdnlite では使用できません。)
-
MDN_DELIMMAP - 特定の文字をピリオド (U+002E FULL STOP) に変換する。
-
MDN_LOCALMAP - ドメイン名のトップレベルドメインに応じて、異なるローカルな マッピングを行う。
-
MDN_NAMEPREP - NAMEPREP に基づいて、正規化、文字のマッピング、使用禁止文字が 含まれているかどうかの判定を行う。
-
MDN_UNASCHECK - Unicode で文字が割り当てられていないコード番号を含んでいないか どうかの判断を行う。
-
MDN_IDNCONV - UTF-8 の文字列を多言語ドメイン用のエンコーディング (Punycode, RACE など) に変換する。
これらに加えて、利便性を配慮して MDN_ENCODE_APP という
フラグも用意されています。
通常、アプリケーションは actions にこの
MDN_ENCODE_APP を指定することになります。
ライブラリとして libmdn を使用している場合、このフラグは次の指定
(MDN_UNASCHECK 以外はすべて行う) と等価です。
MDN_LOCALCONV | MDN_DELIMMAP | MDN_LOCALMAP | MDN_NAMEPREP | MDN_IDNCONV
libmdnlite を使用している場合は、次の指定
(MDN_LOCALCONV、MDN_UNASCHECK 以外はすべて
行う) と等価です。
MDN_DELIMMAP | MDN_LOCALMAP | MDN_NAMEPREP | MDN_IDNCONV
actionsに何も指定しなければ (つまり 0 を指定した場合は)、
文字列は単にコピーされます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_invalid_syntax、
mdn_invalid_name、
mdn_invalid_action、
mdn_buffer_overflow、
mdn_nomemory、
mdn_nofile、
mdn_prohibited
のいずれかです。
libmdnlite 使用時に MDN_LOCALCONV を指定すると、
mdn_invalid_action が返ります。
mdn_decodename
mdn_result_t mdn_decodename(int actions, const char *from, char *to, size_t tolen);
ドメイン名のデコードを行います。 入力文字列 from を変換し、結果を to と tolen で指定される領域に書き込みます。
actions には、デコードにおいて、mdn_decodename
に行わせたい変換動作を指定します。次に挙げるフラグの論理和の値を指定する
ようにします。
指定された動作は、ここに挙げたのと同じ順序でそれぞれ行われます。
-
MDN_IDNCONV - 多言語ドメイン用のエンコーディング (Punycode, RACE など) の文字列 を UTF-8 に変換する。
-
MDN_NAMEPREP - 正しく NAMEPREP が行われた文字列であるかどうかをチェックする。 正しく行われていない場合は、文字列を再び IDN エンコーディングに戻す。
-
MDN_UNASCHECK - 文字列が NAMEPREP の未割り当てコードポイントを含んでいるかどうか チェックする。 正しく行われていない場合は、文字列を再び IDN エンコーディングに戻す。
-
MDN_LOCALCONV - UTF-8 の文字列をローカルエンコーディング (shift_JIS や Big5 など) に変換する。(libmdn でだけ使用できます。libmdnlite では使用できません。)
これらに加えて、利便性を配慮して MDN_DECODE_APP という
フラグも用意されています。
通常、アプリケーションは actions にこの
MDN_DECODE_APP を指定することになります。
ライブラリとして libmdn を使用している場合、このフラグは次の指定と
等価です。
MDN_IDNCONV | MDN_NAMEPREP | MDN_LOCALCONV
libmdnlite を使用している場合は、次の指定と等価です。
MDN_IDNCONV | MDN_NAMEPREP
actionsに何も指定しなければ (つまり 0 を指定した場合は)、
文字列は単にコピーされます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_invalid_syntax、
mdn_invalid_name、
mdn_invalid_action、
mdn_buffer_overflow、
mdn_nomemory、
mdn_nofile、
mdn_prohibited
のいずれかです。
libmdnlite 使用時に MDN_LOCALCONV を指定すると、
mdn_invalid_action が返ります。
mdn_localtoutf8
mdn_result_t mdn_localtoutf8(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_LOCALCONV, from, to, tolen)
と等価です。
この関数は libmdn でだけ使用できます。
libmdnlite で使用すると、mdn_invalid_action が返ります。
mdn_delimitermap
mdn_result_t mdn_delimitermap(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_DELIMMAP, from, to, tolen)
と等価です。
mdn_localmap
mdn_result_t mdn_localmap(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_LOCALMAP, from, to, tolen)
と等価です。
mdn_nameprep
mdn_result_t mdn_nameprep(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_NAMEPREP, from, to, tolen)
と等価です。
mdn_nameprepcheck
mdn_result_t mdn_nameprepcheck(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_decodename(MDN_NAMEPREP, from, to, tolen)
と等価です。
mdn_utf8toidn
mdn_result_t mdn_utf8toidn(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_IDNCONV, from, to, tolen)
と等価です。
mdn_idntoutf8
mdn_result_t mdn_idntoutf8(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_decodename(MDN_IDNCONV, from, to, tolen)
と等価です。
mdn_utf8tolocal
mdn_result_t mdn_utf8tolocal(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_decodename(MDN_LOCALCONV, from, to, tolen)
と等価です。
この関数は libmdn でだけ使用できます。
libmdnlite で使用すると、mdn_invalid_action が返ります。
mdn_localtoidn
mdn_result_t mdn_localtoidn(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_encodename(MDN_ENCODE_APP, from, to, tolen)
と等価です。
mdn_idntolocal
mdn_result_t mdn_idntolocal(const char *from, char *to, size_t tolen);
実体は cpp マクロで、
mdn_decodename(MDN_DECODE_APP, from, to, tolen)
と等価です。
braceモジュール
braceモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
BRACE エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
BRACE エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__brace_open
mdn_result_t
mdn__brace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
BRACEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__brace_close
mdn_result_t
mdn__brace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
BRACEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__brace_convert
mdn_result_t
mdn__brace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
BRACEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
BRACEエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングからBRACE
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
checkerモジュール
checkerモジュールは、ドメイン名に使用できない文字が
含まれているかどうかを検査するためのモジュールです。
現在サポートされている検査方式は次の通りです。
- NAMEPREPの禁止文字の検査
- NAMEPREPの未割り当てコードポイントの検査
- 禁止文字、未割り当てコードポイントを定義したファイルを読み込み、 その記述にしたがった検査
また別の新たな検査方式を追加登録するためのAPIも用意されています。
checkerモジュールは「検査コンテキスト」という概念を用います。
検査に先立ってまず検査コンテキストを作成し、使用する検査方式をコンテキスト
に登録しておきます。
実際の検査処理の際には検査方式ではなく、
この検査コンテキストを指定します。
検査コンテキストの型は
mdn_checker_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_checker *mdn_checker_t;
以下にモジュールの提供するAPI関数を示します。
mdn_checker_initialize
mdn_result_t mdn_checker_initialize(void)
モジュールの初期化処理を行います。本モジュールの他のAPI関数を呼ぶ前に 必ず呼び出してください。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_checker_create
mdn_result_t mdn_checker_create(mdn_checker_t *ctxp)
検査用の空のコンテキストを作成し、ctxp の指す領域に格納します。
返されるコンテキストは空で、検査方式は一つも含まれていません。
検査方式を追加するには
mdn_checker_add、
mdn_checker_addallを用います。
コンテキストで作成された時点では、コンテキストの参照カウントは 1 になって
います。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_checker_destroy
void mdn_checker_destroy(mdn_checker_t ctx)
mdn_checker_create で
作成した検査コンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn_checker_incrref
void mdn_checker_incrref(mdn_checker_t ctx)
mdn_checker_create で
作成した検査コンテキストの参照カウントを一つ増やします。
mdn_checker_add
extern mdn_result_t mdn_checker_add(mdn_checker_t ctx, const char *name)
mdn_checker_create で
作成した検査コンテキストに、name で指定される
検査方式を追加します。一つのコンテキストに複数の検査方式を
追加することができます。
検査方式nameの書式は次のようになります。
-
MDN_CHECKER_PROHIBIT_PREFIX<nameprep-version> - NAMEPREP バージョン <nameprep-version> の禁止文字検査 を行います。
-
MDN_CHECKER_UNASSIGNED_PREFIX<nameprep-version> - NAMEPREP バージョン <nameprep-version> の未割り当て コードポイントの検査を行います。
-
MDN_CHECKER_PROHIBIT_PREFIX fileset:<path> - <path>で指定されたファイルから禁止文字の定義を 読み込み、その内容に従って検査を行います。 ファイルの記述方法については、 セットファイルの形式 の項を参照してください。
-
MDN_CHECKER_UNASSIGNED_PREFIX fileset:<path> - ファイルから未割り当てコードポイントの定義を読み込み、その内容に 従って検査を行います。 ファイルの記述方法については、 セットファイルの形式 の項を参照してください。
-
<prefix>
:<parameter> -
mdn_checker_registerで登録した検査方式 <prefix> による検査を行います。 <parameter> は、登録した関数createに対して 引数<parameter>として渡されます。
MDN_CHECKER_PROHIBIT_PREFIX および
MDN_CHECKER_UNASSIGNED_PREFIX は cpp マクロで、実際
にはそのマクロの値を用います。また、その後ろの fileset や
<nameprep-version> との間に空白を開けてはいけません。
したがって、文字列nameは、実際には次のような方法で生成する
ことになります。
sprintf(name, "%s%s", MDN_CHECKER_PROHIBIT_PREFIX, nameprep_version); sprintf(name, "%sfileset:%s", MDN_CHECKER_UNASSIGNED_PREFIX, file_path);
返される値は
mdn_success、
mdn_invalid_name、
mdn_nomemory
のいずれかです。
mdn_checker_addall
mdn_result_t mdn_checker_addall(mdn_checker_t ctx, const char **names, int nnames)
mdn_checker_addallは一度に複数の検査方式を追加する
ことを除いて、
mdn_checker_addと
同じです。
長さnnamesからなる配列namesの各要素を
検査方式として登録します。
すべての方式の追加に成功するとmdn_successを返します。
登録に失敗した場合、失敗した方式より先に記述されていた方式だけが
コンテキスト ctx に登録された状態になります。
mdn_checker_lookup
mdn_result_t
mdn_checker_lookup(mdn_checker_t ctx, const char *utf8,
const char **found)
UTF-8 でエンコードされた文字列 utf8 を ctx に
指定された検査方式で検査します。
文字列が禁止文字、未割り当てコードポイントを含んでいた場合、
foundにその先頭位置を格納します。
含まれていない場合は、NULLを返します。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
mdn_checker_register
mdn_result_t
mdn_checker_register(const char *prefix,
mdn_checker_createproc_t create,
mdn_checker_destroyproc_t destroy,
mdn_checker_lookupproc_t lookup)
新しい検査方式を登録します。
prefixには、検査方法の名称を指定します。
mdn_checker_add、
mdn_checker_addall
でコンテキストに検査方式を追加する際には、この名称で検査方法を指定
します。
create、destroy、lookupには、それぞれ
mdn_checker_create、
mdn_checker_destroy、
mdn_checker_lookup
の処理が行われる際に、呼び出してほしい関数を指定します。
それぞれの関数は、次のような引数、戻り値でなくてはなりません。
typedef mdn_result_t (*mdn_checker_createproc_t)
(const char *parameter, void **ctxp);
typedef void (*mdn_checker_destroyproc_t)
(void *ctx);
typedef mdn_result_t (*mdn_checker_lookupproc_t)
(void *ctx, const char *utf8, const char **found);
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
converterモジュール
converterモジュールは、文字列のエンコーディング(コードセット)を
変換します。MDN ライブラリは内部処理に UTF-8 エンコーディングの文字列を
使用するため、このモジュールはあるエンコーディングと UTF-8 との間の
相互変換を行います。
現在サポートされているエンコーディングは次の通りです。
-
iconv()がサポートしているエンコーディング方式
iconv() とは汎用的なコードセット変換機能を提供する関数で、 この関数がサポートするエンコーディングをサポートします。 iconv() がサポートするエンコーディングは実装依存なので、 具体的にどのエンコーディングが使用可能なのかは iconv() の ドキュメントをご覧ください。 また、このエンコーディング方式は libmdn でだけ使用できます。 libmdnlite では使用できません。 - 各種の多言語ドメイン名のエンコーディング方式
多言語ドメイン名のために、数多くのエンコーディング方式が提案されましたが、 MDN ライブラリはこのうちの多くに対応しています。 ライブラリが対応しているエンコーディング方式については、 既に廃れたエンコーディング方式 をご覧ください。 このエンコーディング方式は libmdn, libmdnlite どちらのライブラリ でも使用できます。
また、converterモジュールはドメイン名のエンコーディング変換の
ために
特別に設計されたもので、一般的なエンコーディング変換には必ずしも適しません。
例えば Punycode, RACE、DUDE といったエンコーディングはドメイン名の
区切り文字であるピリオドを特別に扱います。
converterモジュールは「コード変換コンテキスト」という概念を
用います。
あるエンコーディングと UTF-8 との相互変換を行うには、まず
そのエンコーディングのコード変換コンテキストを作成します。実際の
コード変換にはエンコーディングを直接指定するのではなく、この
コード変換コンテキストを指定します。コード変換コンテキストの型は
mdn_converter_t 型であり、次のような opaque 型として
定義されています。
typedef struct mdn_converter *mdn_converter_t;
以下にモジュールの提供するAPI関数を示します。
mdn_converter_initialize
mdn_result_t mdn_converter_initialize(void)
モジュールの初期化処理を行います。本モジュールの他のAPI関数を呼ぶ前に 必ず呼び出してください。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_converter_create
mdn_result_t
mdn_converter_create(const char *name, mdn_converter_t *ctxp,
int delayedopen)
name で指定されたエンコーディングと UTF-8 との間の コード変換コンテキストを作成、初期化し、ctxp の指す領域に 格納します。 コンテキストで作成された時点では、コンテキストの参照カウンタは 1 になって います。
ライブラリには Punycode、RACE、DUDE
といったエンコーディングの変換機能が用意されています。
これ以外のエンコーディングが指定された場合には、システムの提供する
iconv() ユーティリティを用いて変換が行われます。
この場合、この関数の呼び出し時にiconv_open() の
呼び出しが行われますが、
delayedopen が真ならば実際に文字列の変換が行われるまで
iconv_open() の呼び出しが遅延されます。
またmdn_converter_register
を用いて新たなローカルエンコーディングを追加することも可能です。
返される値は
mdn_success、
mdn_invalid_name、
mdn_nomemory、
mdn_failure
のいずれかです。
mdn_converter_destroy
void mdn_converter_destroy(mdn_converter_t ctx)
mdn_converter_create で
作成したコード変換コンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn_converter_incrref
void mdn_converter_incrref(mdn_converter_t ctx)
mdn_converter_create で
作成したコード変換コンテキストの参照カウントを一つ増やします。
mdn_converter_convert
mdn_result_t
mdn_converter_convert(mdn_converter_t ctx,
mdn_converter_dir_t dir, const char *from,
char *to, size_t tolen)
mdn_converter_create で
作成したコード変換コンテキストを用いて
文字列 from をコード変換し、結果を to に格納します。
tolen は to の長さです。
dir は変換の方向の指定で、
-
mdn_converter_l2u - コンテキストに設定したエンコーディングからUTF-8への変換
-
mdn_converter_u2l - UTF-8からコンテキストに設定したエンコーディングへの変換
となります。
指定したエンコーディングとは、
mdn_converter_create で
指定したエンコーディングのことを指します。
ISO-2022-JPのように状態をもつエンコーディングを使用した場合、
iconv() と異なり、この関数の呼び出し間で状態は保存されません。
変換は毎回初期状態から始まります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_invalid_name、
mdn_nomemory、
mdn_failure
のいずれかです。
mdn_converter_localencoding
char * mdn_converter_localencoding(mdn_converter_t ctx)
コード変換コンテキスト ctx に設定さたエンコーディング名 を返します。
mdn_converter_isasciicompatible
int mdn_converter_isasciicompatible(mdn_converter_t ctx)
コード変換コンテキスト ctx のローカルエンコーディングが ASCII互換エンコーディングかどうかを返します。ASCII互換エンコーディングなら 1が、そうでないなら0が返ります。
ASCII互換エンコーディング(ASCII-compatible Encoding) とは、 そのエンコーディングでエンコードされたドメイン名が 通常のASCIIのドメイン名と区別できない、つまり英数字および ハイフンのみで構成されるようなエンコーディングのことで、 具体的には Punycode などが相当します。 これらのエンコーディングは 一般にアプリケーションのローカルエンコーディングとして用いられることは ありませんが、DNS プロトコル上でドメイン名を表すためのエンコーディングとしては (従来の DNS サーバ等がなんの変更もなしに使えることもあって) 有力視されている ものです。
mdn_converter_addalias
mdn_result_t mdn_converter_addalias(const char *alias_name, const char *real_name)
エンコーディング名 real_name に対して、alias_name
という別名を登録します。登録した別名は
mdn_converter_create の
name 引数に指定することができます。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_converter_aliasfile
mdn_result_t mdn_converter_aliasfile(const char *path)
ファイル path で指定されるファイルを読み込み、その内容に 従って別名を登録します。 ファイル path は次のような単純な形式の行からなる テキストファイルです。
別名 正式名
また #で始まる行はコメントとみなされます。
返される値は
mdn_success、
mdn_nofile、
mdn_invalid_syntax、
mdn_nomemory
のいずれかです。
mdn_converter_resetalias
mdn_result_t mdn_converter_resetalias(void)
mdn_converter_addalias
や mdn_converter_aliasfile
で登録した別名をリセットし、別名が全く登録されていない初期状態に
戻します。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_converter_register
mdn_result_t
mdn_converter_register(const char *name,
mdn_converter_openproc_t open,
mdn_converter_closeproc_t close,
mdn_converter_convertproc_t convert,
int ascii_compatible)
name という名前のローカルエンコーディングと UTF-8との 間のエンコーディング変換機能を追加します。open、close、 convert は変換等の処理関数へのポインタです。 ascii_compatible にはこのローカルエンコーディングが ASCII互換エンコーディングなら1を、そうでなければ0を指定します。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
debugモジュール
debugモジュールはデバッグ用出力のためのユーティリティ
モジュールです。以下にモジュールの提供するAPI関数を示します。
mdn_debug_hexstring
char * mdn_debug_hexstring(const char *s, int maxbytes)
文字列 s を16進数表示した文字列を返します。
maxbytes は表示する最大の長さで、sが
これを超えた場合には最後に「...」という文字列が付加
されます。
返される文字列のメモリ領域は本関数の保持するスタティック変数の もので、その内容は本関数の次の呼び出し時まで有効です。
mdn_debug_xstring
char * mdn_debug_xstring(const char *s, int maxbytes)
文字列 s の中で、コードが128以上のものを\x{HH}形式で
表示した文字列を返します。
maxbytes は表示する最大の長さで、s が
これを超えた場合には最後に ...が追加されます。
返される文字列のメモリ領域は本関数の保持するスタティック変数の もので、その内容は本関数の次の呼び出し時まで有効です。
mdn_debug_hexdata
char * mdn_debug_hexdata(const char *s, int length, int maxlength)
長さ length のバイト列 s を16進表示した文字列を 返します。
maxbytes は表示する最大のバイト長で、
length がこれを超えた場合には最後に ...が追加されます。
返される文字列のメモリ領域は本関数の保持するスタティック変数の もので、その内容は本関数の次の呼び出し時まで有効です。
mdn_debug_hexdump
void mdn_debug_hexdump(const char *s, int length)
長さ length のバイト列 s の16進ダンプを 標準エラー出力に表示します。
dnモジュール
dnモジュールは、DNS メッセージ内のドメイン名の展開・圧縮を行う
モジュールです。これはリゾルバライブラリのres_comp および
res_expand に
相当する機能を提供します。
このモジュールは本ライブラリの他のモジュールからのみ利用されることを想定して 設計されています。
ドメイン名の圧縮の際は、次に示すmdn__dn_t 型のコンテキスト情報を
使用します。
#define MDN_DN_NPTRS 64
typedef struct {
const unsigned char *msg;
int cur;
int offset[MDN_DN_NPTRS];
} mdn__dn_t;
以下にモジュールの提供するAPI関数を示します。
mdn__dn_expand
mdn_result_t
mdn__dn_expand(const char *msg, size_t msglen,
const char *compressed, char *expanded,
size_t buflen, size_t *complenp)
長さ msglen のDNSメッセージ msg 中の 圧縮されたドメイン名 compressed を展開し、 expanded に結果を格納します。 buflen は expanded の大きさです。 また、compressed の長さが *complenp に格納されます。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_message
のいずれかです。
mdn__dn_initcompress
void mdn__dn_initcompress(mdn__dn_t *ctx, const char *msg)
ドメイン名圧縮用のコンテキスト情報 ctx を初期化します。
この関数はmdn__dn_compress
を呼び出す前に必ず呼び出す必要があります。
msg は圧縮したドメイン名を格納するDNSメッセージの
先頭アドレスです。
mdn__dn_compress
mdn_result_t
mdn__dn_compress(const char *name, char *sptr, size_t length,
mdn__dn_t *ctx, size_t *complenp)
name の指すドメイン名を圧縮して sptr の指す 場所に格納します。length は sptr の空き領域の長さです。 圧縮の際は、ctx に入っている以前に圧縮したドメイン名の情報が 参照されます。 圧縮したドメイン名の長さが complenp に入れられるとともに、 圧縮に必要な情報が ctx に追加されます。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_name
のいずれかです。
delimitermapモジュール
通常、ドメイン名の区切りとして用いるデリミタはピリオド(`.')
だけですが、このdelimitermapモジュールは
ピリオド以外の文字を区切りとして使用できるようにするために、他の文字から
ピリオドへのマッピングを行います。
delimitermapモジュールは「デリミタマップコンテキスト」
という概念を用います。
マッピングに先立ってまずデリミタマップコンテキストを作成し、区切りとして
使用する文字を登録しておきます。
実際のマッピング処理の際にはマッピング方式ではなく、この
マップコンテキストを指定します。
マップコンテキストの型はmdn_delimitermap_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_delimitermap *mdn_delimitermap_t;
以下にモジュールの提供するAPI関数を示します。
mdn_delimitermap_create
mdn_result_t mdn_delimitermap_create(mdn_delimitermap_t *ctxp)
空のデリミタマップコンテキストを作成し、ctxp の指す領域に格納
します。
返されるコンテキストは空で、デリミタは一つも含まれていません。
デリミタを追加するには
mdn_delimitermap_add、
mdn_delimitermap_addall
を用います。
コンテキストで作成された時点では、コンテキストの参照カウントは 1 になって
います。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_delimitermap_destroy
void mdn_delimitermap_destroy(mdn_delimitermap_t ctx)
mdn_delimitermap_create で
作成したマップコンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn_delimitermap_incrref
void mdn_delimitermap_incrref(mdn_delimitermap_t ctx)
mdn_delimitermap_create で
作成したコンテキストの参照カウントを一つ増やします。
mdn_delimitermap_add
extern mdn_result_t mdn_delimitermap_add(mdn_delimitermap_t ctx, unsigned long delimiter)
mdn_delimitermap_create
で作成したコンテキストに、UCS コードポイント delimiter を
ドメイン名のデリミタ (区切り文字)として追加します。
ただし、
mdn_delimitermap_fixを
呼ぶ前でないと、追加することはできません。
mdn_delimitermap_fixを既に呼んだ状態でこの関数を呼ぶと、
mdn_failureを返します。
この関数から返される値は
mdn_success、
mdn_nomemory、
mdn_invalid_codepoint、
mdn_failure
のいずれかです。
mdn_delimitermap_addall
mdn_result_t mdn_delimitermap_addall(mdn_delimitermap_t ctx, const char **names, int nnames)
mdn_delimitermap_addallは一度に複数のデリミタ (区切り文字)
を追加することを除いて、
mdn_delimitermap_addと
同じです。
長さnnamesからなる配列namesの各要素をデリミタとして
登録します。
すべてのデリミタの追加に成功するとmdn_successを返します。
登録に失敗した場合、失敗した方式より先に記述されていたデリミタだけが
コンテキスト ctx に登録された状態になります。
mdn_delimitermap_fix
void mdn_delimitermap_fix(mdn_delimitermap_t ctx)
コンテキスト内に格納されいてるデータの配置を、最適化します。
この関数を利用すると、それ以降は
mdn_delimitermap_addおよび
mdn_delimitermap_addall
によるデリミタの登録はできなくなります。
逆に、この関数を呼ばないと
mdn_delimitermap_map
によるマッピングは行えません。
mdn_delimitermap_map
mdn_result_t
mdn_delimitermap_map(mdn_delimitermap_t ctx, const char *from, char *to,
size_t tolen)
UTF-8 でエンコードされた文字列 from に ctxによる
マッピングを適用します。
ctxに登録されているデリミタ (区切り文字) をピリオド
(`.')にマッピングし、結果を to とtolen
で指定される領域に書き込みます。
この関数を利用するには、あらかじめ mdn_delimitermap_fix を
呼んでおかなければなりません。
mdn_delimitermap_fix が呼ばれていない状態でこの関数を呼ぶと、
mdn_failure を返します。
この関数から返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_failure
のいずれかです。
dudeモジュール
dudeモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
DUDE エンコーディング
とUTF-8との間の変換を行うモジュールです。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
DUDE エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__dude_open
mdn_result_t
mdn__dude_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
DUDEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__dude_close
mdn_result_t
mdn__dude_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
DUDEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__dude_convert
mdn_result_t
mdn__dude_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
DUDEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
DUDEエンコーディングからUTF-8エンコーディングへ、mdn_converter_u2l
ならUTF-8エンコーディングからDUDEエンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
filecheckerモジュール
filecheckerモジュールは、ドメイン名に使用できない文字を定義
したファイルを読み込み、その定義にしたがったドメイン名を検査を行うす
るためのモジュールです。
このモジュールはcheckerモジュール
の下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
checkerモジュールに対して
filecsetによる検査を要求すると、このモジュールが間接的
に呼び出されることになります。
ファイルの記述方法については、 セットファイルの形式 の項を参照してください。
以下にモジュールの提供するAPI関数を示します。
mdn__filechecker_create
mdn_result_t mdn__filechecker_create(const char *file, mdn_filechecker_t *ctxp)
検査ファイルコンテキストを一つ作成します。 ドメイン名に使用できない文字を定義したファイル fileを読み 込み、生成した検査コンテキストに追加します。
返される値は
mdn_success、
mdn_nomemory、
mdn_nofile、
mdn_invalid_syntax
のいずれかです。
mdn__filechecker_destroy
void mdn__filechecker_destroy(mdn_filechecker_t ctx)
mdn__filechecker_create で
作成したコンテキストを削除し、アロケートされたメモリを解放します。
mdn__filechecker_lookup
mdn_result_t
mdn__filechecker_lookup(mdn_filechecker_t ctx, const char *utf8,
const char **found)
UTF-8 でエンコードされた文字列 utf8 を ctx に
指定された検査方式で検査します。
文字列が禁止文字、未割り当てコードポイントを含んでいた場合、
foundにその先頭位置を格納します。
含まれていない場合は、NULLを返します。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
filemapperモジュール
filemapperモジュールは、ドメイン名中の各文字のマッピング規則
を定義したファイルを読み込み、その定義にしたがってマッピングを行うための
モジュールです。
このモジュールはmapperモジュール
の下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
mapperモジュールに対して
filecmapによる検査を要求すると、このモジュールが間接的
に呼び出されることになります。
ファイルの記述方法については、 マップファイルの形式 の項を参照してください。
以下にモジュールの提供するAPI関数を示します。
mdn__filemapper_create
mdn_result_t mdn__filemapper_create(const char *file, mdn_filemapper_t *ctxp)
マップファイルコンテキストを一つ作成します。 マッピング規則を定義したファイル fileを読み 込み、生成した検査コンテキストに追加します。
返される値は
mdn_success、
mdn_nomemory、
mdn_nofile、
mdn_invalid_syntax
のいずれかです。
mdn__filemapper_destroy
void mdn__filemapper_destroy(mdn_filemapper_t ctx)
mdn__filemapper_create で
作成したコンテキストを削除し、アロケートされたメモリを解放します。
mdn__filemapper_map
mdn_result_t
mdn__filemapper_map(mdn__filemapper_t ctx, const char *from,
char *to, size_t tolen);
UTF-8 でエンコードされた文字列 from に ctx で 指定されるマッピングを適用し、その結果を to と tolen で 指定される領域に書き込みます。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
laceモジュール
laceモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
LACE エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
LACE エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__lace_open
mdn_result_t
mdn__lace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
LACEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__lace_close
mdn_result_t
mdn__lace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
LACEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__lace_convert
mdn_result_t
mdn__lace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
LACEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
LACEエンコーディングからUTF-8エンコーディングへ、mdn_converter_u2l
ならUTF-8エンコーディングからLACEエンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
localencodingモジュール
localencodingモジュールはロケール情報を利用して、
アプリケーションの使用しているエンコーディングを推測するモジュールです。
以下にモジュールの提供するAPI関数を示します。
mdn_localencoding_name
const char * mdn_localencoding_name(void)
現在のロケール情報を元に、アプリケーションの使用しているエンコーディング名
(mdn_converter_create() に渡す
名前) を推測して返します。
推測は、システムがnl_langinfo() を備えていればそれを利用し、
そうでなければsetlocale() や環境変数の情報から行われます。
後者の場合には必ずしも正しいエンコーディング名が得られるとは限りません。
ロケール情報から正しい推測ができない場合、もしくはアプリケーションが ロケールと異なるエンコーディングを用いて動作している場合のために、 もし環境変数 MDN_LOCAL_CODESET が定義されていれば、 をアプリケーションのロケールに関わらず、その変数の値をエンコーディング名として 返すようになっています。
logモジュール
logモジュールはMDN ライブラリのログの出力処理を制御する
モジュールです。
ログはデフォルトでは標準エラー出力に書き出されますが、ハンドラを登録する
ことで、別の出力方法に変更することも可能です。
またログレベルを設定することも可能です。ログレベルは次の5段階が
定義されています。
ただし mdn_log_level_dump レベルのログを採取するには、
MDN ライブラリをデバッグオプション付きで作成する必要があります。
詳細は mdn_log_dump を
参照してください。
enum {
mdn_log_level_fatal = 0,
mdn_log_level_error = 1,
mdn_log_level_warning = 2,
mdn_log_level_info = 3,
mdn_log_level_trace = 4,
mdn_log_level_dump = 5
};
以下にモジュールの提供するAPI関数を示します。
mdn_log_fatal
void mdn_log_fatal(const char *fmt, ...)
fatal レベルのログを出力します。このレベルは、プログラムの実行が
不可能であるような致命的なエラーの際に用いられます。
引数はprintf と同じ形式で指定します。
mdn_log_error
void mdn_log_error(const char *fmt, ...)
error レベルのログを出力します。このレベルは、
致命的ではないエラーの際に用いられます。
引数はprintf と同じ形式で指定します。
mdn_log_warning
void mdn_log_warning(const char *fmt, ...)
warning レベルのログを出力します。このレベルは警告メッセージを
表示するために用いられます。
引数はprintf と同じ形式で指定します。
mdn_log_info
void mdn_log_info(const char *fmt, ...)
info レベルのログを出力します。このレベルはエラーではなく、
有用と思われる情報を出力するのに用いられます。
引数はprintf と同じ形式で指定します。
mdn_log_trace
void mdn_log_trace(const char *fmt, ...)
trace レベルのログを出力します。このレベルはAPI関数のトレース
情報を出力するのに用いられます。一般にライブラリのデバッグ目的以外で
このレベルのログを記録する必要はないでしょう。
引数はprintf と同じ形式で指定します。
mdn_log_dump
void mdn_log_dump(const char *fmt, ...)
dump レベルのログを出力します。このレベルはさらにデバッグ用の
パケットデータダンプなどを出力するのに用いられます。
一般にライブラリのデバッグ目的以外でこのレベルのログを記録する
必要はないでしょう。
引数は printf と同じ形式で指定します。
dump レベルはライブラリ内部のデバッグのために設けられたものであり、
mdn_log_setlevel 等で
ログレベルを適切に設定しても通常は出力されません。
出力するためには MDN ライブラリをデバッグオプション付きで作成する必要が
あります。このためには
configure の実行時に --enable-debug オプションを
指定してください。
mdn_log_setlevel
void mdn_log_setlevel(int level)
ログ出力のレベルを設定します。設定したレベルを超えるレベルの
ログは出力されません。この関数でログレベルを設定しない場合、
環境変数 MDN_LOG_LEVEL に設定された整数値が使用されます。
mdn_log_getlevel
int mdn_log_getlevel(void)
現在のログ出力のレベルを表す整数値を取得して返します。
mdn_log_setproc
void mdn_log_setproc(mdn_log_proc_t proc)
ログの出力ハンドラを設定します。proc はハンドラ関数への
ポインタです。もしハンドラを指定しない場合、あるいは proc に
NULL を指定した場合には、ログは標準エラー出力に出力されます。
ハンドラの型 mdn_log_proc_t は次のように定義されています。
typedef void (*mdn_log_proc_t)(int level, const char *msg);
level にはログのレベルが、また msg には表示すべき メッセージ文字列が渡されます。
maceモジュール
maceモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
MACE エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
MACE エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__mace_open
mdn_result_t
mdn__mace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
MACEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__mace_close
mdn_result_t
mdn__mace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
MACEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__mace_convert
mdn_result_t
mdn__mace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
MACEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
MACEエンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングから MACE
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
mapperモジュール
mapperモジュールは、ドメイン名中の文字のマッピングを
行うためのモジュールです。
現在サポートされているマッピング方式は次の通りです。
- NAMEPREPマッピング
- マッピング規則を定義したファイルを読み込み、その記述にしたがった
マッピング
また、別の新たなマッピング方式を追加登録するためのAPIも用意されています。
mapperモジュールは「マップコンテキスト」という概念を用います。
マッピングの実行に先立ってまずマップコンテキストを作成し、使用する
マッピング方式をコンテキストに登録しておきます。
実際のマッピング処理の際にはマッピング方式ではなく、
このマップコンテキストを指定します。
マップコンテキストの型は
mdn_mapper_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_mapper *mdn_mapper_t;
以下にモジュールの提供するAPI関数を示します。
mdn_mapper_initialize
mdn_result_t mdn_mapper_initialize(void)
モジュールの初期化処理を行います。本モジュールの他のAPI関数を呼ぶ前に 必ず呼び出してください。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_mapper_create
mdn_result_t mdn_mapper_create(mdn_mapper_t *ctxp)
マッピング用の空のコンテキストを作成し、ctxp の指す領域に格納
します。
返されるコンテキストは空で、マッピング方式は一つも含まれていません。
マッピング方式を追加するには
mdn_mapper_add、
mdn_mapper_addallを用います。
コンテキストで作成された時点では、コンテキストの参照カウントは 1 になって
います。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_mapper_destroy
void mdn_mapper_destroy(mdn_mapper_t ctx)
mdn_mapper_create で
作成したマップコンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn_mapper_incrref
void mdn_mapper_incrref(mdn_mapper_t ctx)
mdn_mapper_create で
作成したコンテキストの参照カウントを一つ増やします。
mdn_mapper_add
extern mdn_result_t mdn_mapper_add(mdn_mapper_t ctx, const char *name)
mdn_mapper_create で
作成したコンテキストに、name で指定される
マッピング方式を追加します。一つのコンテキストに複数のマッピング方式を
追加することができます。
マッピング方式nameの書式は次のようになります。
- <nameprep-version>
- NAMEPREP バージョン <nameprep-version> のマッピング 規則。
-
filemap:<path> - <path>で指定されたファイルから、マッピング規則を 読み込み、その内容に従ってマッピングを行います。 ファイルの記述方法については、 マップファイルの形式 の項を参照してください。
-
<prefix>
:<parameter> -
mdn_mapper_registerで登録したマッピング方式 <prefix> によるマッピングを 行います。 <parameter> は、登録した関数createに対して 引数<parameter>として渡されます。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
mdn_mapper_addall
mdn_result_t mdn_mapper_addall(mdn_mapper_t ctx, const char **names, int nnames)
mdn_mapper_addallは一度に複数のマッピング方式を追加する
ことを除いて、
mdn_mapper_addと
同じです。
長さnnamesからなる配列namesの各要素を
マッピング方式として登録します。
すべての方式の追加に成功するとmdn_successを返します。
登録に失敗した場合、失敗した方式より先に記述されていた方式だけが
コンテキスト ctx に登録された状態になります。
mdn_mapper_map
mdn_result_t
mdn_mapper_map(mdn_mapper_t ctx, const char *from, char *to,
size_t tolen)
UTF-8 でエンコードされた文字列 from に ctx で
指定されるマッピング方式を適用し、その結果を to と
tolen で指定される領域に書き込みます。
ctx に複数のマッピング方式が含まれている場合、それらが
mdn_mapper_add で
追加した順番に適用されます。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
mdn_mapper_register
mdn_result_t
mdn_mapper_register(const char *prefix,
mdn_mapper_createproc_t create,
mdn_mapper_destroyproc_t destroy,
mdn_mapper_lookupproc_t lookup)
新しいマッピング方式を登録します。
prefixには、マッピング方法の名称を指定します。
mdn_mapper_add、
mdn_mapper_addall
でコンテキストにマッピング方式を登録する際に、この名称でマッピング方法を
指定します。
create、destroy、lookupには、それぞれ
mdn_mapper_create、
mdn_mapper_destroy、
mdn_mapper_map
の処理が行われる際に、呼び出してほしい関数を指定します。
それぞれの関数は、次のような引数、戻り値でなくてはなりません。
typedef mdn_result_t (*mdn_mapper_createproc_t)
(const char *parameter, void **ctxp);
typedef void (*mdn_mapper_destroyproc_t)
(void *ctx);
typedef mdn_result_t (*mdn_mapper_mapproc_t)
(void *ctx, const char *utf8, const char *from, char *to,
size_t tolen);
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mapselectorモジュール
mapselectorモジュールは、
mapperモジュールと同様に、
ドメイン名中の文字のマッピングを行います。
mapselectorは、ドメイン名のトップレベルドメイン毎に異なった
マッピング規則を適当させることができるように mapperを拡張
したものです。
mapselectorモジュールは「マップ選択コンテキスト」という概念を
用います。
マッピングを行うに先立ってまずマップコンテキストを作成し、使用する
マッピング方式をコンテキストに登録しておきます。
実際のマッピング処理の際にはマッピング方式ではなく、
このマップコンテキストを指定します。
マップコンテキストの型は
mdn_mapselector_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_mapselector *mdn_mapselector_t;
以下にモジュールの提供するAPI関数を示します。
mdn_mapselector_initialize
mdn_result_t mdn_mapselector_initialize(void)
モジュールの初期化処理を行います。本モジュールの他のAPI関数を呼ぶ前に 必ず呼び出してください。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_mapselector_create
mdn_result_t mdn_mapselector_create(mdn_mapselector_t *ctxp)
マップ選択用の空のコンテキストを作成し、ctxp の指す領域に格納
します。
返されるコンテキストは空で、マッピング方式は一つも含まれていません。
マッピング方式を追加するには
mdn_mapselector_add、
mdn_mapselector_addallを用います。
コンテキストで作成された時点では、コンテキストの参照カウントは 1 になって
います。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_mapselector_destroy
void mdn_mapselector_destroy(mdn_mapselector_t ctx)
mdn_mapselector_create で
作成したマップコンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn_mapselector_incrref
void mdn_mapselector_incrref(mdn_mapselector_t ctx)
mdn_mapselector_create で
作成したコンテキストの参照カウントを一つ増やします。
mdn_mapselector_mapper
mdn_mapper_t mdn_mapselector_mapper(mdn_mapselector_t ctx, const char *tld)
マップ選択コンテキストctxは、マッピング規則を
トップレベルドメイン毎に1個のmapperモジュールのコンテキストに
格納して管理しています。
この関数は、ctxが保持している、
トップレベルドメインtldに対する
mapperコンテキストを取り出します。
取り出したコンテキストの参照カウントは 2 になっています。
取り出したコンテキストを使い終わったら、必ず
mdn_mapper_destroy
を呼び出して参照カウントを減らして下さい。
mdn_mapselector_add
extern mdn_result_t mdn_mapselector_add(mdn_mapselector_t ctx, const char *tld, const char *name)
mdn_mapselector_create で
作成したコンテキストに、トップレベルドメインがtldのドメイン名
に対するマッピング方式として name を追加します。
一つのコンテキストの各トップドメインに対して、複数のマッピング方式を追加
することができます。
tldには .jpや.tw のようなトップレベル
ドメイン名を指定します。(先頭の `.' は省略可能です。)
加えて、tldに `.' を指定すると、
マッピング規則が定義されていないトップレベルドメインに対する、デフォルト
のマッピング規則を追加します。
同様に`-' を指定すると、トップレベルドメインを持たない
ドメイン名 (`.' を含まないドメイン名) に適当するマッピング
規則を追加します。
マッピング方式nameの書式は、
mdn_mapper_map のものと
変わりません。
mdn_mapper_registerで
登録したマッピング方式も指定することができます。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
mdn_mapselector_addall
mdn_result_t
mdn_mapselector_addall(mdn_mapselector_t ctx, const char *tld,
const char **names, int nnames)
mdn_mapselector_addallは一度に複数のマッピング方式を追加する
ことを除いて、
mdn_mapselector_addと
同じです。
長さnnamesからなる配列namesの各要素を
マッピング方式として登録します。
すべての方式の追加に成功するとmdn_successを返します。
登録に失敗した場合、失敗した方式より先に記述されていた方式だけが
コンテキスト ctx に登録された状態になります。
mdn_mapselector_map
mdn_result_t
mdn_mapselector_map(mdn_mapselector_t ctx, const char *from, char *to,
size_t tolen)
UTF-8 でエンコードされたドメイン名 from に対して、
そのトップレベルドメインに応じて ctx で指定されたマッピング
方式を適用し、その結果を to と tolen で指定される
領域に書き込みます。
ctx に、そのトップレベルドメイン向けのマッピング方式が複数個
含まれている場合、それらが
mdn_mapselector_add で
追加した順番に適用されます。
返される値は
mdn_success、
mdn_nomemory、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
msgheaderモジュール
msgheaderモジュールはDNS メッセージのヘッダの解析、
および組み立てを行うモジュールです。
解析されたヘッダ情報は、次に示す構造体に入ります。各フィールドは DNS メッセージヘッダのフィールドにそのまま対応しているので、説明は省略します。
typedef struct mdn_msgheader {
unsigned int id;
int qr;
int opcode;
int flags;
int rcode;
unsigned int qdcount;
unsigned int ancount;
unsigned int nscount;
unsigned int arcount;
} mdn_msgheader_t;
以下にモジュールの提供するAPI関数を示します。
mdn_msgheader_parse
mdn_result_t
mdn_msgheader_parse(const char *msg, size_t msglen,
mdn_msgheader_t *parsed)
msg と msglen で示されるDNSメッセージのヘッダを 解析し、parsed が示す構造体に格納します。
返される値は
mdn_success、
mdn_invalid_message
のいずれかです。
mdn_msgheader_unparse
mdn_result_t
mdn_msgheader_unparse(mdn_msgheader_t *parsed,
char *msg, size_t msglen)
この関数は
mdn_msgheader_parseの
逆の処理を行います。つまり、parsed で指定された構造体のデータから
DNSメッセージのヘッダを構成し、msg と msglen で
示される領域に格納します。
返される値は
mdn_success、
mdn_buffer_overflow
のいずれかです。
mdn_msgheader_getid
unsigned int mdn_msgheader_getid(const char *msg)
msg で指定されるDNSメッセージから ID を取り出して返します。 この関数はヘッダ全体を解析せずにIDだけ取り出したいときに便利です。 この関数は、msg の指すデータがDNSメッセージのヘッダ長以上ある ことを仮定していますので、必ず呼び出し側で確認してから呼び出すように してください。
mdn_msgheader_setid
void mdn_msgheader_setid(char *msg, unsigned int id)
msg で指定されるDNSメッセージに id で指定される ID を設定します。 この関数も msg の指すデータがDNSメッセージのヘッダ長以上ある ことを仮定していますので、必ず呼び出し側で確認してから呼び出すように してください。
msgtransモジュール
msgtransモジュールはDNS プロキシサーバでの DNS メッセージの
変換処理の大部分を提供するモジュールです。このモジュールは
converterモジュールや
normalizerモジュールなど
他の多くのモジュールの上位モジュールとして実現されています。
DNSプロキシサーバにおけるメッセージ変換処理はおよそ次のようなものです。
まずクライアントからDNSサーバへのメッセージの変換の場合は次の ようになります。
- クライアントから受信したリクエストメッセージを解析し、 クライアント側のエンコーディングを判定します。
- 判定結果を用いて、エンコーディングをUTF-8に変換します。
- 正規化処理を行います。
- エンコーディングを UTF-8からDNSサーバ側で用いられるエンコーディングに 変換します。
- 以上の処理をメッセージに含まれるすべてのドメイン名に対して行い、 変換結果を再び DNS メッセージ形式にまとめて DNS サーバに送信します。
次にDNSサーバからクライアントへのメッセージの変換の場合は次の ようになります。
- DNSサーバから受信したリプライメッセージを解析し、 含まれているすべてのドメイン名に対して、ZLDの除去、UTF-8エンコーディング への変換を行います。
- さらにクライアント側エンコーディングに変換し、ZLDを付加します。
- 変換結果を再び DNS メッセージ形式にまとめてクライアントに送信します。
以下にモジュールの提供するAPI関数を示します。
mdn_msgtrans_translate
mdn_result_t
mdn_msgtrans_translate(mdn_resconf_t resconf,
const char *msg, size_t msglen,
char *outbuf, size_t outbufsize,
size_t *outmsglenp)
msg および msglen で指定されるDNSメッセージを resconf にしたがって変換し、結果をoutbuf および outbufsize で示される領域に格納します。 outmsglenp には変換結果のメッセージ長が格納されます。
返される値は
mdn_success、
mdn_invalid_message、
mdn_invalid_encoding、
mdn_buffer_overflow
のいずれかです。
nameprepモジュール
nameprepモジュールは、NAMEPREP の記述にしたがってドメイン名の
正規化行うためのモジュールです。
現在サポートされているNAMEPREPのバージョンは次の通りです。
-
nameprep-03 -
nameprep-05 -
nameprep-06 -
nameprep-07
nameprepモジュールは「NAMEPREPコンテキスト」という概念を
用います。
正規化に先立ってまずNAMEPREPコンテキストを作成し、使用する
バージョンをコンテキストに登録しておきます。
実際の正規化処理の際には、NAMEPREPバージョンではなく、コンテキストを
指定します。
NAMEPREPコンテキストの型は
mdn_nameprep_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_nameprep *mdn_nameprep_t;
以下にモジュールの提供するAPI関数を示します。
mdn_nameprep_create
mdn_result_t mdn_nameprep_create(const char *version, mdn_nameprep_t *ctxp)
指定されたバージョンversion のNAMEPREPコンテキストを 作成し、ctxp の指す領域に格納します。
返される値は
mdn_success、
mdn_notfound
のいずれかです。
mdn_nameprep_destroy
void mdn_nameprep_destroy(mdn_nameprep_t ctx)
mdn_nameprep_create で
作成したNAMEPREPコンテキストを削除し、アロケートされたメモリを解放します。
mdn_nameprep_map
mdn_result_t
mdn_nameprep_map(mdn_nameprep_t ctx, const char *from, char *to,
size_t tolen)
UTF-8 でエンコードされた文字列 from に ctx で 指定されるマッピング方式を適用し、その結果を to と tolen で指定される領域に書き込みます。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding
のいずれかです。
mdn_nameprep_isprohibited
mdn_result_t
mdn_nameprep_isprohibited(mdn_nameprep_t ctx, const char *utf8,
const char **found)
UTF-8 でエンコードされた文字列 utf8 を ctx に
指定された検査方式で検査します。
文字列が使用を禁止されている文字を含んでいた場合、
foundにその先頭位置を格納します。
含まれていない場合は、NULLを返します。
返される値は
mdn_success、
mdn_invalid_encoding
のいずれかです。
mdn_nameprep_isunassigned
mdn_result_t
mdn_nameprep_isunassigned(mdn_nameprep_t ctx, const char *utf8,
const char **found)
UTF-8 でエンコードされた文字列 utf8 を ctx に
指定された検査方式で検査します。
文字列が未割り当てコードポイントを含んでいた場合、
foundにその先頭位置を格納します。
含まれていない場合は、NULLを返します。
返される値は
mdn_success、
mdn_invalid_encoding
のいずれかです。
normalizerモジュール
normalizerモジュールは文字列の正規化を行うモジュールです。
正規化の方式としては現在次のものが用意されています。
ただし (*) 印が付いた方式は MDN ライブラリの将来のリリースではサポート
されなくなる予定です。
-
ascii-uppercase(*)
ASCII の小文字から大文字への変換 -
ascii-lowercase(*)
ASCII の大文字から小文字への変換 -
unicode-uppercase(*)
Unicode の文字属性を規定した Case Mappings に記述されている小文字大文字マッピングに従った小文字から大文字への変換 -
unicode-lowercase(*)
上記と同じ文書にしたがった大文字から小文字への変換 -
unicode-foldcase(*)
上記と同じ文書にしたがった、大文字と小文字を区別なしに比較する際に行う 変換 -
unicode-form-c(*)
Unicode のバージョンの中で、mDNkit が対応している最も新しい バージョンによる Unicode normalization form C (Unicode normalization form C については、 Unicode Normalization Forms を参照のこと) -
unicode-form-kc
Unicode のバージョンの中で、mDNkit が対応している最も新しい バージョンによる Unicode normalization form KC (Unicode normalization form KC については、 Unicode Normalization Forms を参照のこと) -
unicode-form-d(*)
Unicode のバージョンの中で、mDNkit が対応している最も新しい バージョンによる Unicode normalization form D (Unicode normalization form D については、 Unicode Normalization Forms を参照のこと) -
unicode-form-kd(*)
Unicode のバージョンの中で、mDNkit が対応している最も新しい バージョンによる Unicode normalization form KD (Unicode normalization form KD については、 Unicode Normalization Forms を参照のこと) -
unicode-form-c/3.0.1(*)
Unicode バージョン 3.0.1 による Unicode normalization form C -
unicode-form-kc/3.0.1
Unicode バージョン 3.0.1 による Unicode normalization form KC -
unicode-form-c/3.1.0(*)
Unicode バージョン 3.1.0 による Unicode normalization form C -
unicode-form-kc/3.1.0
Unicode バージョン 3.1.0 による Unicode normalization form KC -
unicode-form-d/3.1.0(*)
Unicode バージョン 3.1.0 による Unicode normalization form D -
unicode-form-kd/3.1.0(*)
Unicode バージョン 3.1.0 による Unicode normalization form KD -
nameprep-03unicode-form-kc/3.0.1の別名 -
nameprep-05unicode-form-kc/3.1.0の別名 -
nameprep-06unicode-form-kc/3.1.0の別名。nameprep-05 と同一。 -
nameprep-07unicode-form-kc/3.1.0の別名。nameprep-05 と同一。
正規化方式は複数併用することも可能で、この場合指定した順に適用されます。 また別の新たな正規化方式を追加登録するためのAPIも用意されています。
normalizerモジュールは「正規化コンテキスト」という概念を用います。
正規化を行うに先立ってまず正規化コンテキストを作成し、使用する
正規化方式をコンテキストに登録しておきます。
実際の正規化処理の際には正規化方式ではなく、
この正規化コンテキストを指定します。
正規化コンテキストの型は
mdn_normalizer_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn_normalizer *mdn_normalizer_t;
以下にモジュールの提供するAPI関数を示します。
mdn_normalizer_initialize
mdn_result_t mdn_normalizer_initialize(void)
モジュールの初期化処理を行います。本モジュールの他のAPI関数を呼ぶ前に 必ず呼び出してください。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_normalizer_create
mdn_result_t mdn_normalizer_create(mdn_normalizer_t *ctxp)
正規化用の空のコンテキストを作成し、ctxp の指す領域に格納します。
返されるコンテキストは空で、正規化方式は一つも含まれていません。
正規化方式を追加するには
mdn_normalizer_add、
mdn_normalizer_addall
を用います。
コンテキストで作成された時点では、コンテキストの参照カウントは 1 になって
います。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_normalizer_destroy
void mdn_normalizer_destroy(mdn_normalizer_t ctx)
mdn_normalizer_create で
作成した正規化コンテキストの参照カウントを一つ減らします。
その結果、カウントが 0 になれば、コンテキストを削除し、アロケートされた
メモリを解放します。
mdn__nomalizer_incrref
void mdn_normalizer_incrref(mdn_normalizer_t ctx)
mdn_normalizer_create で
作成した正規化コンテキストの参照カウントを一つ増やします。
mdn_normalizer_add
mdn_result_t mdn_normalizer_add(mdn_normalizer_t ctx, const char *scheme_name)
mdn_normalizer_create で
作成した正規化コンテキストに、scheme_name で指定される
正規化方式を追加します。一つのコンテキストに複数の正規化方式を
追加することができます。
返される値は
mdn_success、
mdn_invalid_name、
mdn_nomemory
のいずれかです。
mdn_normalizer_addall
mdn_result_t
mdn_normalizer_addall(mdn_normalizer_t ctx, const char **scheme_names,
int nschemes)
mdn_normalizer_addallは一度に複数の正規化方式を追加する
ことを除いて、
mdn_normalizer_addと
同じです。
長さnschemesからなる配列scheme_namesの各要素を
正規化方式として登録します。
すべての方式の追加に成功するとmdn_successが返ります。
登録に失敗した場合、失敗した方式より先に記述されていた方式だけが
コンテキスト ctx に登録された状態になります。
mdn_normalizer_normalize
mdn_result_t
mdn_normalizer_normalize(mdn_normalizer_t ctx,
const char *from, char *to, size_t tolen)
UTF-8 でエンコードされた文字列 from に ctx で
指定される正規化方式を適用し、その結果を to と tolen で
指定される領域に書き込みます。
ctx に複数の正規化方式が含まれている場合、それらが
mdn_normalizer_add で
追加した順番に適用されます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
mdn_normalizer_register
mdn_result_t
mdn_normalizer_register(const char *scheme_name,
mdn_normalizer_proc_t proc)
新しい正規化方式を scheme_name という名前で登録します。 proc はその正規化方式の処理関数へのポインタです。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
raceモジュール
raceモジュールは、多言語ドメイン名のエンコーディング方式の
一つとして提案された
RACE エンコーディング
とUTF-8との間の変換を行うモジュールです。
このモジュールは
converterモジュールの下位モジュール
として実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
RACEエンコーディングとの変換を要求すると、このモジュールが
間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__race_open
mdn_result_t
mdn__race_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
RACEエンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__race_close
mdn_result_t
mdn__race_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
RACEエンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__race_convert
mdn_result_t
mdn__race_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
RACEエンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
RACEエンコーディングからUTF-8エンコーディングへ、mdn_converter_u2l
ならUTF-8エンコーディングからRACEエンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
resモジュール
resモジュールはクライアント側
(アプリケーション)で多言語ドメイン名の処理、つまり
ドメイン名のエンコーディング変換や正規化を行う際の低レベル API を提供します。
このモジュールはあとで説明する
resconfモジュール
とともに用いることを前提に設計されています。
これらのモジュールの提供する API を使用すれば、
converterモジュールや
normalizerモジュールなどの関数を直接
呼び出す必要はありません。
なお、
環境変数 MDN_DISABLE
が設定されている場合は、以下に挙げられた文字列変換用の関数を使用しても
文字列の変換は行われず、元の文字列のままの結果が返されます。
MDN_DISABLE が設定されている環境で文字列の変換を強制的に行う場合や、
アプリケーションでこれらの API 関数を使用するうえで
MDN_DISABLE の設定に関係なく一定の動作を保証したい場合は、
mdn_res_enable
を事前に使用しておかなければなりません。
以下にモジュールの提供するAPI関数を示します。
mdn_res_enable
void mdn_res_enable(int on_off);
通常、 環境変数 MDN_DISABLE が宣言されている場合、 ドメイン名変換処理は行われず、元の文字列のままの結果が返されますが、 この関数はその設定をオーバーライドすることができます。
MDN_DISABLE が設定されているかどうかにかかわらず、 on_off に 0 以外の値を指定してこの関数を使用すると、 それ以降はドメイン名の変換を行うようになります。 0 を指定すると、それとは逆にドメイン名の変換を行なわず、 元の文字列のままの結果を返すようになります。
mdn_res_nameconv
mdn_result_t
mdn_res_nameconv(mdn_resconf_t ctx, const char *insn,
const char *from, char *to, size_t tolen)
文字列fromに対して、多言語ドメイン名に関する変換や検査 を行い、結果をtoおよびtolenで指定された領域 に格納します。 変換や検査は、設定コンテキストctxにしたがって行われます。
具体的にどのような変換および検査を、どういう順番で行うのかは 文字列insnで指定します。 変換や検査の方法は、すべて次のように一文字で表します。 文字列insnにセットされたこれらの文字の並びは、 先頭から順に評価されていきます。
-
l - ローカルエンコーディングから UTF-8 に変換します。
(libmdn でだけ使用できます。libmdnlite では使用できません。) -
L - UTF-8 からローカルエンコーディングに変換します。
(libmdn でだけ使用できます。libmdnlite では使用できません。) -
d - デリミタのマッピングを行います。
-
M - ローカルなマッピングを適用します。
-
m - マッピングを行います。
-
n - 正規化を行います。
-
p - 禁止文字の検査を行います。
-
N - NAMEPREP (マッピング、正規化、禁止文字の検査) を行います。
`
mnp' と等価です。 -
u - 割り当てコードポイントの検査を行います。
-
!m - 正しくマッピングが行われた文字列かどうかのチェックを行います。 正しく行われていない場合は、IDN エンコーディングに変換します。
-
!n - 正しく正規化が行われた文字列かどうかのチェックを行います。 正しく行われていない場合は、IDN エンコーディングに変換します。
-
!p - 文字列に禁止文字が含まれているかどうかのチェックを行います。 含まれている場合は、IDN エンコーディングに変換します。
-
!N - 正しく NAMEPREP が行われた文字列 (マッピング、正規化が行われ、禁止文字 を含んでいない文字列) かどうかのチェックを行います。 正しく行われていない場合は、IDN エンコーディングに変換します。
-
!u - 文字列に未割り当てコードポイントが含まれているかどうかのチェックを 行います。 含まれている場合は、IDN エンコーディングに変換します。
-
I - UTF-8からIDNエンコーディングに変換します。
-
i - IDNエンコーディングからUTF-8に変換します。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_invalid_name、
mdn_invalid_action、
mdn_invalid_nomemory、
mdn_invalid_nomapping、
mdn_invalid_prohibited、
mdn_failure
のいずれかです。
libmdnlite 使用時に l や L を含んだ insn を
mdn_res_nameconv() に与えると、mdn_invalid_action
が返ります。
mdn_res_localtoucs
mdn_result_t
mdn_res_localtoucs(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列をローカルエンコーディングから UTF-8 に変換します。 次の処理と等価です。
mdn_res_nameconv(ctx, "l", from, to, tolen)
この関数は libmdn でだけ使用できます。
libmdnlite で使用すると、mdn_invalid_action が返ります。
mdn_res_ucstolocal
mdn_result_t
mdn_res_ucstolocal(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列を UTF-8 からローカルエンコーディングに変換します。 次の処理と等価です。
mdn_res_nameconv(ctx, "L", from, to, tolen)
この関数は libmdn でだけ使用できます。
libmdnlite で使用すると、mdn_invalid_action が返ります。
mdn_res_delimitermap
mdn_result_t
mdn_res_delimitermap(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対してデリミタのマッピングを行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "d", from, to, tolen)
mdn_res_localmap
mdn_result_t
mdn_res_localmap(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対してローカルなマッピングを適用します。 次の処理と等価です。
mdn_res_nameconv(ctx, "M", from, to, tolen)
mdn_res_map
mdn_result_t
mdn_res_map(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対してマッピングを行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "m", from, to, tolen)
mdn_res_normalize
mdn_result_t
mdn_res_normalize(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対して正規化を行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "n", from, to, tolen)
mdn_res_prohibitcheck
mdn_result_t
mdn_res_prohibitcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対して禁止文字の検査を行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "p", from, to, tolen)
mdn_res_nameprep
mdn_result_t
mdn_res_nameprep(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対して NAMEPREP を行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "N", from, to, tolen)
mdn_res_nameprepcheck
mdn_result_t
mdn_res_nameprepcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
正しく NAMEPREP が行われた文字列 (マッピング、正規化が行われ、禁止文字 を含んでいない文字列) かどうかのチェックを行います。 正しく行われていない場合は、IDN エンコーディングに変換します。 次の処理と等価です。
mdn_res_nameconv(ctx, "!N", from, to, tolen)
mdn_res_unassignedcheck
mdn_result_t
mdn_res_unassignedcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
文字列に対して未割り当てコードポイントの検査を行います。 次の処理と等価です。
mdn_res_nameconv(ctx, "u", from, to, tolen)
mdn_res_ucstodns
mdn_result_t
mdn_res_ucstodns(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen);
文字列をUTF-8からIDNエンコーディングに変換します。 次の処理と等価です。
mdn_res_nameconv(ctx, "I", from, to, tolen)
mdn_res_dnstoucs
mdn_result_t
mdn_res_dnstoucs(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen);
文字列をIDNエンコーディングからUTF-8に変換します。 次の処理と等価です。
mdn_res_nameconv(ctx, "i", from, to, tolen)
resconfモジュール
resconfモジュールはクライアント側
(MDN ライブラリやアプリケーション)で多言語ドメイン名の処理を行う際に
参照される
mDNkit設定ファイルを読み込み、
ファイルの設定にしたがった初期化を実行します。また設定情報を取り出す
機能を提供します。
resconfモジュールは「設定コンテキスト」という概念を用います。
設定ファイルに記述された設定はこの設定コンテキストに格納され、この
コンテキストを引数にして API 関数を呼び出すことによって
設定された値を取り出すことができます。
設定コンテキストの型は mdn_resconf_t 型であり、次のような
opaque 型として定義されています。
typedef struct mdn_resconf *mdn_resconf_t;
このモジュールは単体でも使用できますが、
resモジュールと組み合わせることによって、
クライアント側での多言語ドメイン名の処理を簡単に行うことができるように
設計されています。
以下にモジュールの提供するAPI関数を示します。
mdn_resconf_initialize
mdn_result_t mdn_resconf_initialize(void)
多言語ドメイン名の処理を行う際に必要な初期化を実行します。 本モジュールの他のAPI関数を呼ぶ前に必ず呼び出してください。 本モジュールが使用する他のモジュールの初期化もすべて行うので、これ以外の初期化 関数を呼び出す必要はありません。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_resconf_create
mdn_result_t mdn_resconf_create(mdn_resconf_t *ctxp)
設定コンテキストを作成、初期化し、ctxp の指す領域に格納します。
初期状態では、まだ設定ファイルの内容は読み込まれていません。
読み込むためには
mdn_resconf_loadfile を実行する必要があります。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_resconf_destroy
void mdn_resconf_destroy(mdn_resconf_t ctx)
mdn_resconf_loadfile
mdn_result_t mdn_resconf_loadfile(mdn_resconf_t ctx, const char *file)
file で指定される
mDNkit設定ファイルの内容を読み込み、
設定内容を設定コンテキスト ctx に格納します。
file が NULL の場合にはデフォルトの設定ファイルの
内容を読み込みます。
すでに設定ファイルが読み込まれているコンテキストに対して、 別の設定ファイルの内容を読み込むこともできます。その場合には、 設定コンテキストに格納されていた前の設定ファイルの内容はすべて消え、 新たに読み込んだ設定ファイルの内容で置き換わります。
返される値は
mdn_success、
mdn_nofile、
mdn_invalid_syntax、
mdn_invalid_name、
mdn_nomemory
のいずれかです。
mdn_resconf_defaultfile
char * mdn_resconf_defaultfile(void)
デフォルトの設定ファイルのパス名を返します。 これは mDNkit のコンパイル時の設定によって決まりますが、特に指定しなければ
/usr/local/etc/mdn.conf
です。
mdn_resconf_getidnconverter
mdn_converter_t mdn_resconf_getidnconverter(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、IDNエンコーディングと
UTF-8との間の文字コード変換を行うためのコード変換コンテキストを返します。
コンテキストにIDNエンコーディングが指定されていない場合には
NULL を返します。
コード変換コンテキストについては
converterモジュール の項をご覧ください。
mdn_resconf_getlocalconverter
mdn_converter_t mdn_resconf_getlocalconverter(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、ローカルエンコーディングと
UTF-8 との間の文字コード変換を行うためのコード変換コンテキストを返します。
ローカルエンコーディングが判別できなかった場合には NULL を
返します。
コード変換コンテキストについては
converterモジュール の項をご覧ください。
mdn_resconf_getmapper
mdn_mapper_t mdn_resconf_getmapper(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、正規化処理を行うための
マップコンテキストを返します。コンテキストにマッピング方式が
指定されていない場合には NULL を返します。
マップコンテキストについては
mapperモジュール の項をご覧ください。
mdn_resconf_getnormalizer
mdn_normalizer_t mdn_resconf_getnormalizer(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、正規化処理を行うための
正規化コンテキストを返します。コンテキストに正規化方式が指定されていない
場合には NULL を返します。
正規化変換コンテキストについては
normalizerモジュール の項を
ご覧ください。
mdn_resconf_getprohibit
mdn_checker_t mdn_resconf_getprohibit(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、禁止文字の検査処理を
行うための検査コンテキストを返します。コンテキストに禁止文字の検査方式が
指定されていない場合には NULL を返します。
検査コンテキストについては
checkerモジュール の項を
ご覧ください。
mdn_resconf_getunassigned
mdn_checker_t mdn_resconf_getunassigned(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、未割り当てコードポイントの
検査処理を行うための正規化コンテキストを返します。コンテキストに
未割り当てコードポイントの検査方式が指定されていない場合には
NULL を返します。
検査コンテキストについては
checkerモジュール の項を
ご覧ください。
mdn_resconf_getdelimitermap
mdn_delimitermap_t mdn_resconf_getdelimitermap(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、デリミタのマッピングを
行うためのデリミタマップコンテキストを返します。コンテキストにデリミタが
指定されていない場合には NULL を返します。
デリミタマップコンテキストについては
delimitermapモジュール の項を
ご覧ください。
mdn_resconf_getmapselector
mdn_mapselector_t mdn_resconf_getmapselector(mdn_resconf_t ctx)
設定コンテキスト ctx の情報を元に、トップレベルドメインに
応じたローカルなマッピング処理を行うためのマップ選択コンテキストを
返します。コンテキストにローカルなマッピング方式が指定されていない
場合には NULL を返します。
マップ選択コンテキストについては
mapselectorモジュール の項を
ご覧ください。
mdn_resconf_setidnconverter
mdn_result_t
mdn_resconf_setidnconverter(mdn_resconf_t ctx,
mdn_converter_t idn_converter)
コード変換コンテキストidn_converterの情報をもとに、
IDN エンコーディングと UTF-8 との間の文字コード変換を行うための
変換方式を設定コンテキストctxにセットします。
idn_converter に NULL を渡した場合、変換方式
は未指定の状態となります。
コード変換コンテキストについては
converterモジュール の項をご覧ください。
mdn_resconf_setlocalconverter
mdn_result_t
mdn_resconf_setlocalconverter(mdn_resconf_t ctx,
mdn_converter_t local_converter)
コード変換コンテキストlocal_converterの情報をもとに、
ローカルエンコーディングと UTF-8 との間の文字コード変換を行うための
変換方式を設定コンテキストctxにセットします。
local_converter に NULL を渡した場合、
ローカルエンコーディングには自動判別したエンコーディングが用いられます。
コード変換コンテキストについては
converterモジュール の項をご覧ください。
mdn_resconf_setmapper
mdn_result_t mdn_resconf_setmapper(mdn_resconf_t ctx, mdn_mapper_t mapper)
マップコンテキストmapperの情報をもとに、マッピングを行うための
方式を設定コンテキストctxにセットします。mapper に
NULL を渡した場合、マッピング方式は未指定の状態となります。
マップコンテキストについては
mapperモジュール の項をご覧ください。
mdn_resconf_setnormalizer
mdn_result_t
mdn_resconf_setnormalizer(mdn_resconf_t ctx,
mdn_normalizer_t normalizer)
正規化コンテキストnormalizerの情報をもとに、正規化方式を
設定コンテキストctxにセットします。normalizer に
NULL を渡した場合、正規化方式は未指定の状態となります。
正規化変換コンテキストについては
normalizerモジュール の項を
ご覧ください。
mdn_resconf_setprohibit
mdn_result_t
mdn_resconf_setprohibit(mdn_resconf_t ctx,
mdn_checker_t prohibit_checker)
検査コンテキストprohibit_checkerの情報をもとに、
禁止文字の検査を行うための検査方式を設定コンテキストctxに
セットします。prohibit_checker に NULL を
渡した場合、検査方式は未指定の状態となります。
検査コンテキストについては
checkerモジュール の項を
ご覧ください。
mdn_resconf_setunassigned
mdn_result_t
mdn_resconf_setunassigned(mdn_resconf_t ctx,
mdn_checker_t unassigned_checker)
検査コンテキストunassigned_checkerの情報をもとに、
未割り当てコードポイントの検査を行うための検査方式を設定コンテキスト
ctxにセットします。
unassigned_checker に NULL を渡した場合、
検査方式は未指定の状態となります。
検査コンテキストについては
checkerモジュール の項を
ご覧ください。
mdn_resconf_setdelimitermap
mdn_result_t
mdn_resconf_setdelimitermap(mdn_resconf_t ctx,
mdn_delimitermap_t delimiter_mapper)
デリミタマップコンテキストdelimiter_mapperの情報をもとに、
デリミタを設定コンテキストctxにセットします。
delimiter_mapper に NULL を渡した場合、
デリミタは未指定の状態となります。
デリミタマップコンテキストについては
delimitermapモジュール の項を
ご覧ください。
mdn_resconf_setmapselector
mdn_result_t
mdn_resconf_setmapselector(mdn_resconf_t ctx,
mdn_mapselector_t map_selector)
マップ選択コンテキストmap_selectorの情報をもとに、
ローカルなマッピング方式を設定コンテキストctxにセットします。
map_selector に NULL を渡した場合、
マッピング方式は未指定の状態となります。
マップ選択コンテキストについては
mapselectorモジュール の項を
ご覧ください。
mdn_resconf_setidnconvertername
mdn_result_t
mdn_resconf_setidnconvertername(mdn_resconf_t ctx, const char *name,
int flags)
IDN エンコーディングを設定コンテキストctxにセットします。
idn_converter に NULL を渡した場合、
IDN エンコーディングは未指定の状態となります。
mdn_resconf_setlocalconvertername
mdn_result_t
mdn_resconf_setlocalconvertername(mdn_resconf_t ctx, const char *name,
int flags)
ローカルエンコーディングを設定コンテキストctxにセットします。
local_converter に NULL を渡した場合、自動判別した
エンコーディングがセットされます。
mdn_resconf_addallmappernames
mdn_result_t
mdn_resconf_addallmappernames(mdn_resconf_t ctx, const char **names,
int nnames)
namesとnnamesに記されたマッピング方式を、すべて 設定コンテキストctxに追加します。
mdn_resconf_addallnormalizernames
mdn_result_t
mdn_resconf_addallnormalizernames(mdn_resconf_t ctx, const char **names,
int nnames)
namesとnnamesに記された正規化方式を、すべて 設定コンテキストctxに追加します。
mdn_resconf_addallprohibitnames
mdn_result_t
mdn_resconf_addallprohibitnames(mdn_resconf_t ctx, const char **names,
int nnames)
namesとnnamesに記された禁止文字の検査方式を、すべて 設定コンテキストctxに追加します。
mdn_resconf_addallunassignednames
mdn_result_t
mdn_resconf_addallunassignednames(mdn_resconf_t ctx, const char **names,
int nnames)
namesとnnamesに記された未割り当てコードポイントの 検査方式をすべて設定コンテキストctxに追加します。
mdn_resconf_addalldelimitermapucs
mdn_result_t
mdn_resconf_addalldelimitermapucs(mdn_resconf_t ctx,
unsigned long *v, int nv);
コードポイントの配列vとその長さnvで表された
デリミタをすべて設定コンテキストctxに追加します。
この関数でデリミタを追加した場合、
mdn_res_nameconvを用いた
デリミタのマッピングを行う前に必ず
mdn_resconf_fixdelimitermap
を呼び出して、デリミタの追加をこれ以上行わないことを宣言する必要があります。
mdn_resconf_fixdelimitermap
mdn_result_t mdn_resconf_fixdelimitermap(mdn_resconf_t ctx)
デリミタの追加をこれ以上行わないことを宣言します。
mdn_resconf_addalldelimitermapucs
を用いてデリミタの追加を行ったときは、この関数を呼んでおかないと
mdn_res_nameconvによる
デリミタのマッピングが成功しません。
mdn_resconf_allallmapselectornames
mdn_result_t
mdn_resconf_addallmapselectornames(mdn_resconf_t ctx, const char *tld,
const char **names, int nnames)
トップレベルドメインtld に対するローカルなマッピング方式と して、namesとnnamesに記されたものをすべて 設定コンテキストctxに追加します。
mdn_resconf_setnameprepversion
mdn_result_t
mdn_resconf_setnameprepversion(mdn_resconf_t ctx,
const char *version)
設定コンテキストctxのNAMEPREPのバージョンをversion にセットします。
resultモジュール
resultモジュールはライブラリの各関数が返す
mdn_result_t型の値を扱うモジュールで、
値からそのコードに対応するメッセージへの変換を提供します。
以下にモジュールの提供するAPI関数を示します。
mdn_result_tostring
char * mdn_result_tostring(mdn_result_t result)
mdn_result_t型の値 result に対応する
メッセージ文字列を返します。
未定義のコードに対しては unknown result code という文字列が
返されます。
selectiveencodeモジュール
selectiveencodeモジュールはゾーンマスタファイル等のテキストの
中から非ASCII文字を含むドメイン名を探し出すモジュールです。
もちろんテキストのどの部分がドメイン名なのかを判定することは一般的には
不可能なので、実際には次のような大きな仮定を置くことによって
近似的に実現しています。
- 非ASCII文字はドメイン名の中にのみ現れる
具体的には次のようなアルゴリズムを用いてドメイン名の領域検出を行います。
- テキストを走査して、非ASCII文字を探す。
- 見つかった非ASCII文字の前後の文字を調べ、 その文字を含み、かつ他の非ASCII文字あるいは従来の(多言語化されていない) ドメイン名として使用可能な文字だけからなる範囲を求める。
- 求めた範囲をドメイン名として返す。
以下にモジュールの提供するAPI関数を示します。
mdn_selectiveencode_findregion
mdn_result_t
mdn_selectiveencode_findregion(const char *s,
char **startp, char **endp)
UTF-8でエンコードされた文字列 s を走査して、最初に出現する 非ASCII文字を含むドメイン名の領域を求め、その先頭を指すポインタを startp に、領域の直後の文字を指すポインタを endp に それぞれ格納します。
返される値は
mdn_success、
mdn_notfound
のいずれかです。
strhashモジュール
strhashモジュールは文字列をキーとするハッシュ表を実現する
モジュールです。
ハッシュ表は
converterモジュールや
normalizerモジュールなどライブラリの
他のモジュールで使用されます。
非常に一般的なハッシュ表の実装であり、特筆すべき点はありません…
一つだけあります。登録はできますが削除の機能がありません。本ライブラリでは
必要ないからです。
ハッシュ表のサイズは要素の総数が増えるに従って大きくなります。
ハッシュ表は次に示す mdn_strhash_t 型の opaque データとして
表されます。
typedef struct mdn_strhash *mdn_strhash_t;
以下にモジュールの提供するAPI関数を示します。
mdn_strhash_create
mdn_result_t mdn_strhash_create(mdn_strhash_t *hashp)
空のハッシュ表を作成し、そのハンドルを hashp の指す領域に 格納します。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_strhash_destroy
void mdn_strhash_destroy(mdn_strhash_t hash)
mdn_strhash_create で作成した
ハッシュ表を削除し、確保したメモリを解放します。
mdn_strhash_put
mdn_result_t
mdn_strhash_put(mdn_strhash_t hash, const char *key,
void *value)
mdn_strhash_create で作成した
ハッシュ表 hash にキー key、値 value の組を
登録します。
文字列 key はコピーされますので、この関数の呼び出し後
key の指すメモリを解放しても、文字列の内容を書き換えても
影響はありません。これに対して value の内容はコピーされないので
注意してください (もちろんよく考えてみればコピーされないことは自明ですが)。
同じキーを使用して複数回登録した場合、最後に登録されたものだけが 有効です。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn_strhash_get
mdn_result_t
mdn_strhash_get(mdn_strhash_t hash,
const char *key, void **valuep)
ハッシュ表 hash からキー key を持つ要素を検索し、 対応する要素があればその値を valuep に格納します。
返される値は
mdn_success、
mdn_noentry
のいずれかです。
mdn_strhash_exists
int mdn_strhash_exists(mdn_strhash_t hash, const char *key)
ハッシュ表 hash にキー key を持つ要素があれば 1を、なければ 0 を返します。
ucsmapモジュール
ucsmapモジュールは、文字のマッピング規則を登録するための
モジュールです。
このモジュールは、
filemapperモジュール
の下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
以下にモジュールの提供するAPI関数を示します。
mdn__ucsmap_create
mdn_result_t mdn__ucsmap_create(mdn_ucsmap_t *ctxp)
UCSマップコンテキストを一つ作成します。 ただし、作成した時点のコンテキストには、マッピング規則は一つも登録されて いません。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn__ucsmap_destroy
void mdn__ucsmap_destroy(mdn_ucsmap_t ctx)
mdn__ucsmap_create で
作成したコンテキストを削除し、アロケートされたメモリを解放します。
mdn__ucsmap_add
void
mdn__ucsmap_add(mdn_ucsmap_t ctx, unsigned long v, unsigned long *map,
size_t maplen)
mdn__ucsmap_create で
作成したコンテキストに Unicode コードポイントvのマッピング
規則を登録します。
マップ後のシーケンスを map、maplenで指定します。
ただし、mdn__ucsmap_fixを
を呼ぶ前でないと、マッピング規則を登録することはできません。
mdn__ucsmap_fixを既に呼んだ状態でこの関数を呼ぶと、
mdn_failureを返します。
返される値は
mdn_success、
mdn_nomemory、
mdn_failure
のいずれかです。
mdn__ucsmap_fix
void mdn__ucsmap_fix(mdn_ucsmap_t ctx)
コンテキスト内に格納されいてるデータの配置を、最適化します。
この関数を利用すると、それ以降は
mdn__ucsmap_add
によるマッピング規則の登録はできなくなります。
逆に、この関数を呼ばないと
mdn__ucsmap_map
による文字のマッピングは行えません。
mdn__ucsmap_map
mdn_result_t
mdn_ucsmap_map(mdn_ucsmap_t ctx, unsigned long v, unsigned long *to,
size_t tolen, size_t *maplenp);
Unicode のコードポイント v のマップ後のシーケンスをto に格納します。領域toの大きさをtolenで渡し、 実際のマップ後のシーケンスの長さはmaplenp に格納されます。
この関数を利用するには、あらかじめ mdn__ucsmap_fix を
呼んでおかなければなりません。
mdn__ucsmap_fix が呼ばれていない状態でこの関数を呼ぶと、
mdn_failure を返します。
返される値は
mdn_success、
mdn_nomapping、
mdn_failure
のいずれかです。
ucssetモジュール
ucssetモジュールは、文字の登録を行うためのモジュールです。
このモジュールは、
filecheckerモジュールおよび
delimitermapモジュール
の下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
以下にモジュールの提供するAPI関数を示します。
mdn__ucsset_create
mdn_result_t mdn__ucsset_create(mdn_ucsset_t *ctxp)
UCSセットコンテキストを一つ作成します。 作成したばかりのコンテキストには、文字は一つも登録されていません。
返される値は
mdn_success、
mdn_nomemory
のいずれかです。
mdn__ucsset_destroy
void mdn__ucsset_destroy(mdn_ucsset_t ctx)
mdn__ucsset_create で
作成したコンテキストを削除し、アロケートされたメモリを解放します。
mdn__ucsset_add
void mdn__ucsset_add(mdn_ucsset_t ctx, unsigned long v)
mdn__ucsset_create で
作成したコンテキストに Unicode コードポイントvを登録します。
ただし、mdn__ucsset_fixを
を呼ぶ前でないと、文字を登録することはできません。
mdn__ucsset_fixを既に呼んだ状態でこの関数を呼ぶと、
mdn_failureを返します。
返される値は
mdn_success、
mdn_invalid_code、
mdn_nomemory、
mdn_failure
のいずれかです。
mdn__ucsset_addrange
void mdn__ucsset_addrange(mdn_ucsset_t ctx, unsigned long from, unsigned long to)
mdn__ucsset_create で
作成したコンテキストに、fromからtoまでの
Unicodeコードポイント(両端を含む) をすべて登録します。
ただし、mdn__ucsset_fixを
呼ぶ前でないと、文字を登録することはできません。
mdn__ucsset_fixを既に呼んだ状態でこの関数を呼ぶと、
mdn_failureを返します。
返される値は
mdn_success、
mdn_invalid_code
mdn_nomemory、
mdn_failure
のいずれかです。
mdn__ucsset_fix
void mdn__ucsset_fix(mdn_ucsset_t ctx)
コンテキスト内に格納されいてるデータの配置を、最適化します。
この関数を利用すると、それ以降は
mdn__ucsset_addおよび
mdn__ucsset_addrange
による文字の登録はできなくなります。
逆に、この関数を呼ばないと
mdn__ucsset_lookup
による文字の判定は行えません。
mdn__ucsset_lookup
mdn_result_t mdn__ucsset_lookup(mdn_ucsset_t ctx, unsigned long v, int *found)
Unicode のコードポイント v が ctx に含まれて いるかどうかを検査します。 含まれていれば *foundに1を、含まれていなければ0を格納し ます。
この関数を利用するには、あらかじめ mdn__ucsset_fix を
呼んでおかなければなりません。
mdn__ucsset_fix が呼ばれていない状態でこの関数を呼ぶと、
mdn_failure を返します。
返される値は
mdn_success、
mdn_nomemory、
mdn_failure
のいずれかです。
unicodeモジュール
unicodeモジュールは、
UnicodeData.txt
に記述されている、Unicode の各種文字属性を取得するモジュールです。なお、
Unicode.txt に記述されているデータの意味、およびファイル形式については
UnicodeData File Formatをご覧ください。
本ライブラリの多くのモジュールは Unicode のデータを UTF-8エンコードされた
文字列形式で扱いますが、このモジュールは unsigned long 型の
データとして扱います。含まれる値は UCS-4 です。
Unicode で定義されている文字属性などのデータには、いくつかのバージョンが
存在し、それぞれ少しずつ異なります。したがって特定のバージョンを
用いてデータを取得することができるように、本モジュールの提供する API 関数
にはバージョンを指定するためのキーを引数として指定するようになっています。
このキーの型は mdn__unicode_version_t 型であり、
次のような opaque 型として定義されています。
typedef struct mdn__unicode_ops *mdn__unicode_version_t;
このモジュールでは Unicode 文字の大文字小文字の相互変換機能も 提供しています。 これは Unicode Technical Report #21: Case Mappings で 定義されているものです。 Unicode 文字の中にはごく一部ですが大文字小文字の変換をする際に 文脈情報を必要とするものがあり、これは次のような列挙型のデータで指定します。
typedef enum {
mdn__unicode_context_unknown,
mdn__unicode_context_final,
mdn__unicode_context_nonfinal
} mdn__unicode_context_t;
文脈が FINAL の場合には mdn__unicode_context_final を、また
NON_FINAL の場合には mdn__unicode_context_nonfinal を指定します。
mdn__unicode_context_unknown は文脈情報がわからない (調べていない)
ことを示します。
文脈情報に関して詳しくは上記文献をご覧ください。
以下にモジュールの提供するAPI関数を示します。
mdn__unicode_create
mdn_result_t mdn__unicode_create(const char *version, mdn__unicode_version_t *versionp)
version で指定されるバージョンに対応するキーを作成し、
versionp の指す領域に格納します。
version には例えば "3.0.1" のように、バージョンを
示す文字列を指定します。
もし NULL を指定した場合には、
本モジュールがサポートしている中で最新のバージョンに対応するキーを
作成します。
返される値は
mdn_success、
mdn_notfound (指定されたバージョンをサポートしていない場合)
のいずれかです。
mdn__unicode_destroy
void mdn__unicode_destroy(mdn__unicode_version_t version)
mdn__unicode_create で
作成したキー version を削除します。
mdn__unicode_canonicalclass
int
mdn__unicode_canonicalclass(mdn__unicode_version_t version,
unsigned long c);
version で指定されるバージョンの文字属性データを使用して、
Unicode 文字 c の Canonical Combining Class を
求めます。
Canonical Combining Class が定義されていない文字については 0 を返します。
ただし version は
mdn__unicode_create で
作成したキーです。
mdn__unicode_decompose
mdn_result_t
mdn__unicode_decompose(mdn__unicode_version_t version,
int compat, unsigned long *v, size_t vlen,
unsigned long c, int *decomp_lenp)
Unicode 文字 c を
version で指定されるバージョンの
Unicode 文字属性データの CharacterDecomposition Mapping
にしたがって decompose し、その結果を
v および vlen で指定される領域に書き込みます。
compat の値が真なら Compatibility Decomposition を、
偽ならCanonical Decomposition を行います。
ただし version は
mdn__unicode_create で
作成したキーです。
decompose は再帰的に行われます。つまりCharacter Decomposition Mapping にしたがって分解した各文字についてさらに decompose 処理が行われます。
返される値は
mdn_success、
mdn_notfound、
mdn_nomemory
のいずれかです。
mdn__unicode_compose
mdn_result_t
mdn__unicode_compose(mdn__unicode_version_t version,
unsigned long c1, unsigned long c2, unsigned long *compp)
c1 と c2 の2文字の Unicode 文字のシーケンスを
version で指定されるバージョンの
Unicode 文字属性データの Character Decomposition Mapping
にしたがって compose し、その結果を compp の指す領域に書き込みます。
必ず Canonical Composition が行われます。
ただし version は
mdn__unicode_create で
作成したキーです。
返される値は
mdn_success、
mdn_notfound
のいずれかです。
mdn__unicode_iscompositecandidate
int
mdn__unicode_iscompositecandidate(mdn__unicode_version_t version,
unsigned long c)
version で指定されるバージョンの Unicode 文字属性データを用いて、
Unicode文字 c から始まる Canonical Composition が存在するか
どうかを調べ、存在する可能性があれば 1 を可能性がなければ 0 を返します。
これはヒント情報であり、1が返ってきたとしても実際には Composition が
存在しないこともあり得ます。逆に 0 が返ってくれば確実に存在しません。
ただし version は
mdn__unicode_create で
作成したキーです。
Unicode の全文字の中で Canonical Composition の先頭となる文字は数少ないので、
mdn__unicode_compose の
検索のオーバヘッドを減らすためにあらかじめデータをスクリーニングする目的に
使用することができます。
mdn__unicode_toupper
mdn_result_t
mdn__unicode_toupper(mdn__unicode_version_t version,
unsigned long c, mdn__unicode_context_t ctx,
unsigned long *v, size_t vlen, int *convlenp)
version で指定されるバージョンの
Unicode 文字属性データの Uppercase Mapping 情報
情報および SpecialCasing.txtの情報にしたがって
Unicode文字 c を大文字に変換し、結果を
v の指す領域に格納します。vlen はあらかじめ
v に確保した領域の大きさです。変換結果の文字数は
*convlenp に返されます。
変換結果が複数の文字になることがあることに注意してください。
またロケール依存の変換は行いません。
ただし version は
mdn__unicode_create で
作成したキーです。
ctx は文字 c の出現する
文脈情報です。
ほとんどの文字では変換の際に文脈情報は不要なため、
通常は mdn__unicode_context_unknown を指定しておくことが
できます。
もし文脈情報が必要な場合、本関数は戻り値として
mdn_context_requiredを返すので、文脈情報を取得してから改めて
呼び出すことが可能です。
文脈情報の取得には
mdn__unicode_getcontext を使用します。
もし対応する大文字が存在しない場合には c がそのまま v に格納されます。
返される値は
mdn_success、
mdn_context_required、
mdn_buffer_overflow
のいずれかです。
mdn__unicode_tolower
mdn_result_t
mdn__unicode_tolower(mdn__unicode_version_t version,
unsigned long c, mdn__unicode_context_t ctx,
unsigned long *v, size_t vlen, int *convlenp)
version で指定されるバージョンの
Unicode 文字属性データの Lowercase Mapping 情報
および SpecialCasing.txtの情報にしたがって
Unicode文字 c を小文字に変換します。
使用方法は、大文字への変換を行う mdn__unicode_toupper() と同じですので、そちらを参照してください。
mdn__unicode_getcontext
mdn__unicode_context_t
mdn__unicode_getcontext(mdn__unicode_version_t version,
unsigned long c)
version で指定されるバージョンの Unicode 文字属性データを用いて、
大文字小文字変換で用いられる文脈情報を返します。
文脈情報を取得するには次のようにします。
まず大文字小文字変換の対象文字に続く次の文字を取得し、この関数を
呼び出します。もし返される値が mdn__unicode_context_final
あるいは mdn__unicode_context_nonfinal のいずれかであれば
それが求める文脈情報です。
mdn__unicode_context_unknown の場合にはさらに続く文字を取得し、
この関数を呼び出します。このようにして mdn__unicode_context_final
か mdn__unicode_context_nonfinal かいずれかの値が得られるまで
処理を繰り返します。もし文字列の最後まで来た場合には、文脈は
mdn__unicode_context_final となります。
具体的にはこの関数は次のような処理を行います。
Unicode 文字 c の "General Category" 属性を参照し、
それが "Lu" "Ll" "Lt" のいずれかであれば
mdn__unicode_context_nonfinal を、"Mn" であれば
mdn__unicode_context_unknown を、それ以外であれば
mdn__unicode_context_final を返します。
unormalizeモジュール
unormalizeモジュールは、Unicode で定義されている標準の正規化を
行うモジュールです。Unicode の正規化は
Unicode Technical Report #15: Unicode Normalization Forms
で定義されています。本モジュールはこの文書にあげられた4つの正規化形式を
実装しています。
正規化に用いる具体的なデータは、Unicode のバージョンによってそれぞれ
少しずつ異なります。そこで
本モジュールの提供する API 関数は
unicodeモジュールのものと同様に
バージョンを指定するためのキーを引数として指定するようになっています。
キーの作成および削除には、それぞれunicodeモジュールの
mdn__unicode_create および
mdn__unicode_destroy を
使用します。
以下にモジュールの提供するAPI関数を示します。
mdn__unormalize_formc
mdn_result_t
mdn__unormalize_formc(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
UTF-8でエンコードされた文字列 from に対して
version で指定されるバージョンの
正規化 Unicode Normalization Form C を適用し、その結果を
to および tolen で指定される領域に書き込みます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_buffer_overflow、
mdn_nomemory
のいずれかです。
mdn__unormalize_formd
mdn_result_t
mdn__unormalize_formd(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
UTF-8でエンコードされた文字列 from に対して
version で指定されるバージョンの
正規化 Unicode Normalization Form D を適用し、その結果を
to および tolen で指定される領域に書き込みます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_buffer_overflow、
mdn_nomemory
のいずれかです。
mdn__unormalize_formkc
mdn_result_t
mdn__unormalize_formkc(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
UTF-8でエンコードされた文字列 from に対して
version で指定されるバージョンの
正規化 Unicode Normalization Form KC を適用し、その結果を
to および tolen で指定される領域に書き込みます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_buffer_overflow、
mdn_nomemory
のいずれかです。
mdn__unormalize_formkd
mdn_result_t
mdn__unormalize_formkd(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
UTF-8でエンコードされた文字列 from に対して
version で指定されるバージョンの
正規化 Unicode Normalization Form KD を適用し、その結果を
to および tolen で指定される領域に書き込みます。
返される値は
mdn_success、
mdn_invalid_encoding、
mdn_buffer_overflow、
mdn_nomemory
のいずれかです。
utf5モジュール
utf5モジュールはドメイン名のエンコーディング方式の一つとして
提案された
UTF-5
エンコーディング の基本処理を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
以下にモジュールの提供するAPI関数を示します。
mdn_utf5_getwc
int
mdn_utf5_getwc(const char *s, size_t len,
unsigned long *vp)
UTF-5でエンコードされた長さ len バイトの文字列 s の 先頭の文字を取り出し、UCS-4 に変換して vp の指す領域に格納すると ともに、文字の (UTF-5エンコードでの) バイト数を返します。 もし len が短すぎて文字の途中で終わっていたり、エンコーディングが 間違っている場合には 0 が返されます。
mdn_utf5_putwc
int mdn_utf5_putwc(char *s, size_t len, unsigned long v)
UCS-4 文字 v をUTF-5エンコーディングに変換し、s および len で指定される領域に書き込むとともに、書き込んだバイト数を 返します。ただし len が短すぎて書き込めない場合には0を返します。
書き込んだUTF-5文字列は NUL 文字で終端されていません。
utf6モジュール
utf6モジュールは、多言語ドメイン名のエンコーディング方式
の一つとして提案された
UTF-6 エンコーディング
とUTF-8との間の変換を行うモジュールです。
ただし、
既に廃れたエンコーディング方式
となっていますので、取り扱いには注意して下さい。
このモジュールは
converterモジュールの
下位モジュールとして実装されており、
アプリケーションがこのモジュールを直接呼び出すことはありません。
converterモジュールに対して
UTF-6 エンコーディング
との変換を要求すると、このモジュールが間接的に呼び出されることになります。
以下にモジュールの提供するAPI関数を示します。
mdn__utf6_open
mdn_result_t
mdn__utf6_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
UTF-6エンコーディングとの変換をオープンします。実際には何もしません。
常に mdn_successを返します。
mdn__utf6_close
mdn_result_t
mdn__utf6_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
UTF-6エンコーディングとの変換をクローズします。実際には何もしません。
常に mdn_successを返します。
mdn__utf6_convert
mdn_result_t
mdn__utf6_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
UTF-6エンコードされた文字列とUTF-8エンコードされた文字列の相互変換を
行います。
入力文字列 from を変換し、結果を to と
tolen で指定される領域に書き込みます。
dir がmdn_converter_l2uなら
UTF-6エンコーディングからUTF-8エンコーディングへ、
mdn_converter_u2lならUTF-8エンコーディングからUTF-6
エンコーディングへの変換となります。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
mdn_nomemory
のいずれかです。
utf8モジュール
utf8モジュールはUTF-8 でエンコードされた文字列の基本処理を行う
モジュールです。
以下にモジュールの提供するAPI関数を示します。
mdn_utf8_mblen
int mdn_utf8_mblen(const char *s)
UTF-8 文字列 s の先頭文字の長さ(バイト数)を返します。 もし s が指すバイトが UTF-8 の先頭バイトとして正しくないものである 場合には 0 を返します。
この関数は s の先頭バイトのみを調べて長さを返します。したがって 2バイト目以降に不正なバイトがある可能性が存在します。特に途中に NUL バイトが ある可能性もあるので、s が正当な UTF-8 文字列であることが確実では ない場合には気をつける必要があります。
mdn_utf8_getmb
int mdn_utf8_getmb(const char *s, size_t len, char *buf)
長さ len バイトの UTF-8 文字列 s の先頭の1文字を buf にコピーし、コピーしたバイト数を返します。 もし len が短すぎたり、s が指す文字が UTF-8 として 正しくない場合にはコピーは行わず、0 を返します。
buf は任意の UTF-8 エンコーディングの文字が保持できる大きさ でなければなりません。すなわち、6バイト以上の長さを持っている必要があります。
書き込んだUTF-8文字列は NUL 文字で終端されていません。
mdn_utf8_getwc
int
mdn_utf8_getwc(const char *s, size_t len,
unsigned long *vp)
mdn_utf8_getmb とほぼ同じですが、
s から取り出した文字を
UCS-4に変換して vp の指す領域に格納するところが異なります。
mdn_utf8_putwc
int mdn_utf8_putwc(char *s, size_t len, unsigned long v)
UCS-4 文字 v を UTF-8 エンコーディングに変換して、 s および len で指定される領域に書き込むとともに、 書き込んだバイト数を返します。v の値が不正であったり len が短すぎた場合には 0 を返します。
書き込んだUTF-8文字列は NUL 文字で終端されていません。
mdn_utf8_isvalidstring
int mdn_utf8_isvalidstring(const char *s)
NUL 文字で終端された文字列 s が正しい UTF-8 エンコーディング であるかどうか調べ、正しければ 1 を、正しくなければ 0 を返します。
mdn_utf8_findfirstbyte
char *
mdn_utf8_findfirstbyte(const char *s,
const char *known_top)
文字列 known_top 中の s が指すバイトを含む
UTF-8 文字の先頭バイトを調べて返します。その文字が正しい UTF-8
エンコーディングではない場合、known_top から s までの
間に先頭バイトがなかった場合には NULL を返します。
utilモジュール
utilモジュールは他のモジュールで使われるユーティリティー的な
機能を提供するモジュールです。
大文字小文字の区別をしない文字列照合や UTF-8 と UTF-16 の相互変換機能などを
提供しています。
以下にモジュールの提供するAPI関数を示します。
mdn_util_casematch
int mdn_util_casematch(const char *s1, const char *s2, size_t n)
文字列 s1 と s2 の先頭から最大 n バイトを
比較し、同一かどうかを判定します。
ASCII 文字の大文字と小文字 (つまり A から Z と a から z) は同一とみなします。
同一であれば 1 を、違っていれば 0 を返します。
これは多くのシステムで用意されている strcasencmp と返り値の仕様を
除けばほぼ同様の機能を提供する関数です。
mdn_util_domainspan
const char * mdn_util_domainspan(const char *s, const char *end)
ASCII ドメイン名として使用できる文字の範囲を求めます。 s から始めて end まで (ただし end の 指す文字は含まない) の各文字が ASCII の アルファベット、数字、ハイフンのいずれかであるか検査していき、 そうでない文字の最初の出現位置を返します。 すべての文字がアルファベット、数字、ハイフンのいずれかである場合には、 end を返します。
mdn_util_validstd13
int mdn_util_validstd13(const char *s, const char *end)
s と end で示される (部分) 文字列が、 ASCII ドメイン名のラベル (ピリオドで区切られたそれぞれの部分) と して正しい形式かどうかを検査します。 ただし end は最後の文字の次の文字を指すとします。 また end が NULL の場合には s から NUL 文字までの部分が検査対象となります。
次の条件を満たす文字列を正しい形式と判定します。
- ASCII のアルファベット、数字、ハイフンのみから構成されていること
- 先頭の文字と最後の文字はいずれもハイフンではないこと
正しい形式であれば 1 を、そうでなければ 0 を返します。
mdn_util_utf8toutf16
mdn_result_t
mdn_util_utf8toutf16(const char *utf8, size_t fromlen,
unsigned short *utf16, size_t tolen, size_t *reslenp)
長さ fromlen の UTF-8 形式の文字列 utf8 を UTF-16 形式 (16bit 整数の配列) に変換し、結果を utf16 に格納します。 tolen は utf16 の指す領域の大きさ (文字数) です。 *reslenp には変換後の文字列の長さが格納されます。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
のいずれかです。
mdn_util_utf16toutf8
mdn_result_t
mdn_util_utf16toutf8(const unsigned short *utf16, size_t fromlen,
char *utf8, size_t tolen, size_t *reslenp)
長さ fromlen の UTF-16 形式のデータ (16bit 整数の配列) utf8 を UTF-8 形式の文字列に変換し、 結果を utf8 に格納します。 tolen は utf8 の指す領域の大きさ (バイト数) です。 *reslenp には変換後の文字列の長さが格納されます。
返される値は
mdn_success、
mdn_buffer_overflow、
mdn_invalid_encoding、
のいずれかです。
versionモジュール
versionモジュールは、MDN ライブラリのバージョンに関する
機能を提供します。
以下にモジュールの提供するAPI関数を示します。
mdn_version_getstring
const char * mdn_version_getstring(void);
MDN ライブラリのバージョン番号を表現した文字列を返します。
