

MDN Library Specification
Function Overview
The MDN library (libmdn, libmdnlite) is a group of modules that provide various processing with respect to multilingual domain name conversion. This library provides the following features.
- Encoding (code set) conversion
- Normalization of character strings based on NAMEPREP
- Analysis and reassembly of DNS messages
- Loading of client configuration files
All features are implemented in libmdn, however some of the feature of "Encoding (code set) conversion" is left out. For details of the feature left out, refer to Encoding (code set) conversion. How to use the feature not left out is quite as same as libmdn.
Unless it is specially noted, the description of this document is about common to both libmdn and libmdnlite.
Encoding (code set) conversion
Converts character string encoding and returns the result. Inside the MDN library, character strings are all handled as UTF-8 encoding. This module provides the following functions.
- Conversion from certain encoding methods to UTF-8
- Conversion from UTF-8 to certain encoding methods
Encoding is roughly divided into the following two types.
- Encoding used by applications (SJIS, EUC, etc.)
- Special encoding designed to be used for multilingual domain names (Punycode, RACE, etc.)
About this, libmdn supports both encoding method, however libmdnlite supports only the later encoding method.
For the former encoding conversion, iconv() function is used in libmdn.
In other words, in libmdnlite which supports the former encoding method, iconv() is not used.
For the later encoding method, a unique conversion function is implemented and used in libmdn and libmdnlite.
Normalization of character strings based on NAMEPREP
According to the descriptions provided in NAMEPREP, normalization-related modules are responsible for performing normalization of given domain name character strings and, in the character strings, mapping of characters and checking for inclusion of prohibited character and unassigned codepoints.
Domain name mapping based on local rules
These functions perform local rule-based character mapping in addition to NAMEPREP.
Analysis and assembly of DNS messages
In the DNS proxy server (mdnsproxy), encoded domain names included in DNS messages sent from the client are converted and normalized and the result is sent to the DNS server. This process is comprised of the following functions:
- Analyzes DNS messages and extracts domain names
- Re-constructs DNS messages using converted domain names
Local encoding identification
Automatically identifies the local encoding (code set) used by the application program. Basically, the application locale information is used, though the local encoding (code set) can also be specified using an environment variable.
Loading of client configuration file
When the application linked to the MDN library is used to perform conversion or normalization, the encoding and normalization method to be used is described in the configuration file. A function is provided to load this file.
Module list
The MDN library consists of the following modules.
-
acemodule - Provides the common processes used by the amcacez and race domain name conversion modules.
-
altdudemodule - Conversion module for the proposed AltDUDE encoding domain name encoding method.
-
amcacemmodule - Conversion module for the proposed AMC-ACE-M encoding domain name encoding method.
-
amcaceomodule - Conversion module for the proposed AMC-ACE-O encoding domain name encoding method.
-
amcacermodule - Conversion module for the proposed AMC-ACE-R encoding domain name encoding method.
-
amcacevmodule - Conversion module for the proposed AMC-ACE-V encoding domain name encoding method.
-
amcacewmodule - Conversion module for the proposed AMC-ACE-W encoding domain name encoding method.
-
amcacezmodule - Conversion module for the proposed Punycode (it was AMC-ACE-Z before) encoding domain name encoding method.
-
apimodule - Provides a high-level interface for applications to perform encoding conversion and normalization of domain names.
-
bracemodule - Conversion module for the proposed BRACE encoding domain name encoding method.
-
checkermodule - Checks whether characters that cannot be used in a domain name are included therein.
-
convertermodule - Conversion module for character string encoding (code set).
-
debugmodule - Utility module for debug output.
-
delimitermapmodule - Maps specific characters within a domain name to a period (.).
-
dnmodule - Extraction/compression module for domain names inside DNS messages.
-
dudemodule - Conversion module for the proposed DUDE encoding domain name encoding method.
-
filecheckermodule - Loads a file that defines characters that cannot be used in a domain name, and checks whether a given character string contains characters that cannot be used.
-
filemappermodule - Loads a file that defines character mapping rules, and maps characters within a domain name character string.
-
lacemodule - Conversion module for the proposed LACE encoding domain name encoding method.
-
localencodingmodule - Guesses which encoding is used by the application.
-
logmodule - Controls MDN library log output processing.
-
macemodule - Conversion module for the proposed MACE encoding domain name encoding method.
-
mappermodule - Performs mapping for the characters in the domain name.
-
mapselectormodule - Performs local mapping for the top level domain of a given domain name.
-
msgheadermodule - Analyzes the header of the DNS message.
-
msgtransmodule - Converts the DNS message at the DNS proxy server.
-
nameprepmodule - Performs domain normalization, mapping, and prohibited character checking according to the desriptions provided in NAMEPREP.
-
normalizermodule - Normalizes character strings.
-
racemodule - Conversion module for the proposed RACE encoding domain name encoding method.
-
resmodule - Provides a lower lever interface to perform encoding conversion or normalization of domain names by the application.
-
resconfmodule - Provides an interface to perform encoding conversion or normalization of domain names by the application.
-
resultmodule - Handles the result code returned by each library function.
-
selectiveencodemodule - Finds domain names that include non-ASCII characters.
-
strhashmodule - Implements a hash table that uses character strings as keys.
-
ucsmapmodule - Registers character mapping rules and performs mapping.
-
ucssetmodule - Performs character registration.
-
unicodemodule - Obtains various Unicode character properties.
-
unormalizemodule - Performs standard normalization defined by Unicode.
-
utf5module - Performs basic processing of the proposed UTF-5 encoding domain name encoding method.
-
utf6module - Conversion module for the proposed UTF-6 encoding domain name encoding method.
-
utf8module - Performs basic processing of UTF-8 encoding character strings.
-
utilmodule - Provides common functions used by other modules.
-
versionmodule - Obtains library version information.
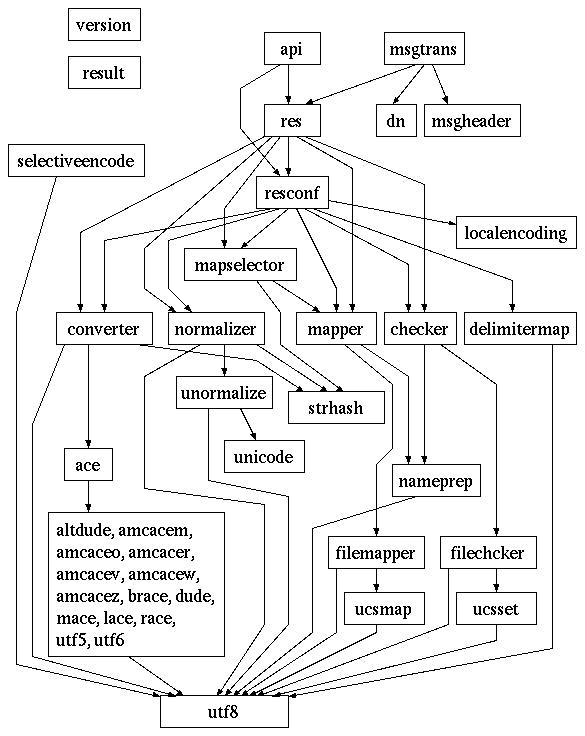
The following diagram shows the invoking relationship of
modules. debug and log modules called by
most modules and util modules that store common functions
are omitted in the diagram.
Already outdated encodings
As understand to see Module list, many encodings proposed for multilingual domain names are implemented in MDN library.
However, many of the encodings are dealed as already outdated encodings in mDNkit.
The outdated encodings cannot be compiled by usually installation step for mDNkit.
To use, need to specify --enable-extra-ace option of configure in installation.
At the same time, in future MDN library, these encodings subject to unsupport. Please keep in mind this point.
The position of each encodings is the following.
- Normally suported encodings
- Punycode (it was AMC-ACE-Z before), DUDE, RACE
- Already outdated encodings
- AltDUDE, AMC-ACE-M, AMC-ACE-O, AMC-ACE-R, AMC-ACE-W, AMC-ACE-V, BRACE, LACE, MACE, UTF-5, UTF-6
Details of Modules
The specifications of all modules included in MDN library are explained below. First, the values returned by functions used commonly by the modules are explained, then each module is discussed in detail.
Values returned by API functions
Almost all API functions of the MDN library return values of
mdn_result_t, which is an enumeration type value. The
values and their meanings are explained below.
-
mdn_success - Processing was successful.
-
mdn_notfound - The target of search processing could not be found.
-
mdn_invalid_encoding - Incorrect conversion of encoded input character string.
-
mdn_invalid_syntax - Incorrect file format.
-
mdn_invalid_name - Specified name is incorrect.
-
mdn_invalid_message - Entered DNS message is incorrect.
-
mdn_invalid_action - Invalid character string conversion method specified.
-
mdn_invalid_codepoint - Codepoint value of input character lies outside of specified range.
-
mdn_buffer_overflow - Insufficient buffer to store result.
-
mdn_noentry - Specified item does not exist.
-
mdn_nomemory - Memory allocation failed.
-
mdn_nofile - Failed to load specified file.
-
mdn_nomapping - Conversion could not be performed correctly because a character in the encoded character string (code set) does not exist in the target conversion character set.
-
mdn_context_required - Indicates that context information is required to correctly convert uppercase characters to lowercase characters.
-
mdn_prohibited - Input character string includes character whose use is prohibited.
-
mdn_failure - Indicates that an error occurred that does not fall into any of the above categories.
ace module
The ace module provides the common processes used by the
amcacez, race domain name
conversion modules. This module is packaged
as a low-level module for the converter
module, and is not called by the application. It is indirectly
called when Punycode or RACE encoding conversion
is requested of the converter
module.
This module provides the following API functions.
mdn__ace_convert
mdn_result_t
mdn__ace_convert(mdn__ace_t ctx, mdn_converter_dir_t dir,
const char *from, char *to, size_t tolen)
Performs bi-directional conversion between ACE character strings and
UTF-8 character strings. It converts the input character string
from and writes it to the area specified by to
and tolen. If dir is
mdn_converter_l2u, it converts from ACE to UTF-8; if dir
is mdn_converter_u2l, it converts from UTF-8 to ACE.
The ctx type, mdn_ace_t, is defined as shown
below; and maintains the ACE prefix, suffix, and a pointer to the
actual conversion function.
enum { mdn__ace_prefix, mdn__ace_suffix };
typedef mdn_result_t
(*mdn__ace_proc_t)(const char *from, size_t fromlen,
char *to, size_t tolen);
typedef struct {
int id_type; /* mdn__ace_prefix/mdn__ace_suffix */
const char *id_str; /* prefix/suffix string */
mdn__ace_proc_t encoder;/* encode procedure */
mdn__ace_proc_t decoder;/* decode procedure */
} mdn__ace_t;
The following processing is performed when dir is
mdn_converter_l2u:
- The domain name character string specified in from is disassembled into labels, and steps 2 through 5 below are performed on each label.
- The ACE prefix or suffix is extracted from the data specified in ctx, and each label character string is checked to determine if it matches this. If it does not match, the label character string is copied as is without being converted.
- If the label character string does match, the matched prefix or suffix is removed, the decode function specified by ctx is called, and the label character string is converted to a UTF-8 encoded label character string.
- The result of the decode function is checked to determine if it is valid as a conventional ASCII domain name. If valid, the label cannot be converted back to the original ACE, so an error results.
- The encoding function specified by ctx is called, and the decoded character string is returned once more to ACE. It is then compared to the original ACE character string, and, if it does not match, error results.
- The conversion result of each label is assembled into a domain name and stored in the area specified by to.
The following processing is performed when dir is
mdn_converter_u2l:
- The domain name character string specified by from is disassembled into labels, and steps 2 through 4 below are performed on each label.
- The label character string is checked to determine if it is valid as a conventional ASCII domain name. If valid, there is no need to convert it to ACE, so it is copied as is.
- The encoding function specified by ctx is called, and the label character string is converted to ACE.
- The ACE prefix or suffix is extracted from the data specified by ctx, and it is added to the character string resulting from the ACE conversion.
- The conversion result of each label is assembled into a domain name and stored in the area specified by to.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
altdude module
The altdude module converts between the proposed
AltDUDE
encoding multilingual domain name encoding method and UTF-8
encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly from the application. It is called indirectly when
conversion to or from AltDUDE encoding is requested of
the converter module.
This module provides the following API functions.
mdn__altdude_open
mdn_result_t
mdn__altdude_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to and from AltDUDE encoding. Actually, this does not
do anything. Always returns mdn_success.
mdn__altdude_close
mdn_result_t
mdn__altdude_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-M encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__altdude_convert
mdn_result_t
mdn__altdude_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AltDUDE encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AltDUDE encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AltDUDE encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcacem module
The amcacem module converts between the proposed
AMC-ACE-M encoding multilingual domain name encoding method and
UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from AMC-ACE-M encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcacem_open
mdn_result_t
mdn__amcacem_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from AMC-ACE-M encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacem_close
mdn_result_t
mdn__amcacem_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-M encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacem_convert
mdn_result_t
mdn__amcacem_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AMC-ACE-M encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AMC-ACE-M encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-M encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcaceo module
The amcaceo module converts between the proposed
AMC-ACE-O
encoding multilingual domain name encoding method and UTF-8
encoding. This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from AMC-ACE-O encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcaceo_open
mdn_result_t
mdn__amcaceo_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from AMC-ACE-O encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcaceo_close
mdn_result_t
mdn__amcaceo_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-O encoding, but does not actually
perform any action. Always returns mdn_success.
mdn__amcaceo_convert
mdn_result_t
mdn__amcaceo_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AMC-ACE-O encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AMC-ACE-O encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-O encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcacer module
The amcacer module converts between the proposed
AMC-ACE-R encoding multilingual domain name encoding method and
UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from AMC-ACE-R encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcacer_open
mdn_result_t
mdn__amcacer_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from AMC-ACE-R encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacer_close
mdn_result_t
mdn__amcacer_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-R encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacer_convert
mdn_result_t
mdn__amcacer_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AMC-ACE-R encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AMC-ACE-R encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-R encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcacev module
The amcacev module converts between the proposed
AMC-ACE-V encoding multilingual domain name encoding method and
UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from AMC-ACE-V encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcacev_open
mdn_result_t
mdn__amcacev_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from AMC-ACE-V encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacev_close
mdn_result_t
mdn__amcacev_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-V encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacev_convert
mdn_result_t
mdn__amcacev_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AMC-ACE-V encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AMC-ACE-V encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-V encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcacew module
The amcacew module converts between the proposed
AMC-ACE-W encoding multilingual domain name encoding method and
UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from AMC-ACE-W encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcacew_open
mdn_result_t
mdn__amcacew_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from AMC-ACE-W encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacew_close
mdn_result_t
mdn__amcacew_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from AMC-ACE-W encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacew_convert
mdn_result_t
mdn__amcacew_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between AMC-ACE-W encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
AMC-ACE-W encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-W encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
amcacez module
The amcacez module converts between the proposed
Punycode encoding (it was AMC-ACE-Z before) multilingual domain name encoding method and
UTF-8 encoding.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from Punycode encoding is requested of
the converter module.
This module provides the following API functions.
mdn__amcacez_open
mdn_result_t
mdn__amcacez_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from Punycode encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacez_close
mdn_result_t
mdn__amcacez_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from Punycode encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__amcacez_convert
mdn_result_t
mdn__amcacez_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between Punycode encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
Punycode encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to Punycode encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
api module
The api module provides a high-level interface for the
applications to perform encoding conversion and
normalization of domain names.
Since general applications will use this module, it has been designed
to enable the developer to easily perform a series of processes on
multilingual domain names. Any developer who wishes to perform
specialized processing not supported by this module can use the
res module, which provides a
lower-level interface.
In addition, in the case of setting environment variable MDN_DISABLE, even if using the functions for string conversion which are cited in the following, conversion of strings is not performed, but returned the result as the original string.
In the case of performing conversion of strings forcibly in setting MDN_DISABLE environment, or wanting to assure constant performance whether setting MDN_DISABLE or not in using these API functions in applications, mdn_enable must be used on ahead.
This module provides the following API functions.
mdn_enable
void mdn_enable(int on_off);
Usually, in the case of defining environment variable MDN_DISABLE, process of domain name conversion is not performed, but the result as the original string is returned, however this function can overrides the setting.
Whether MDN_DISABLE is set or not, if this function is used with setting a value other than 0 for on_off, conversion of domain name become to perform subsequently. If setting 0, contrary conversion of domain name is not performed, but the result as the original string is returned.
mdn_nameinit
mdn_result_t mdn_nameinit(void);
Initializes the entire library, using configuration settings it loads
from a predetermined file (mdn.conf).Initialization will
therafter not be performed for any subsequent calls to this
function. If mdn_encodename or
mdn_decodename (described below) is called before this
function is called, initialization is automatically performed before
encoding or decoding processing occurs.
One of the following values is returned:
mdn_success,
mdn_nofile,
mdn_invalid_syntax,
mdn_invalid_name,
mdn_nomemory.
mdn_encodename
mdn_result_t mdn_encodename(int actions, const char *from, char *to, size_t tolen);
Encodes a domain name. It converts the input character string in from and writes the result to the area specified by to and tolen.
Specify the encoding behavior you wish mdn_encodename to
perform in actions. Specify such that the value is
yielded by logically OR'ing the flags that are listed below (Ex:
MDN_NAMEPREP | MDN_IDNNCONV). The specified behaviors are
perfomed in the order given below.
-
MDN_LOCALCONV - Converts local encoding character strings (shift_JIS, Big5, etc.), to UTF-8. (It is available only in libmdn, not available in libmdnlite.)
-
MDN_DELIMMAP - Converts specific characters to periods (U+002E FULL STOP).
-
MDN_LOCALMAP - Performs local mapping for the top level domain of a given domain name.
-
MDN_NAMEPREP - Based on the descriptions provided in NAMEPREP, performs normalization, character mapping, and determination of whether invalid characters are included in a domain name.
-
MDN_UNASCHECK - Determines if the domain name includes a code number that is not assigned in Unicode.
-
MDN_IDNCONV - Converts UTF-8 character strings to a multilingual domain encoding (Punycode, RACE, etc.)
Additionally, for the developer's convenience, we also provide
MDN_ENCODE_APP
Usually applications will set this MDN_ENCODE_APP to
actions.
In the case of using libmdn as library, this flag is equivalent the following specification (performing all except for MDN_UNASCHECK).
MDN_LOCALCONV | MDN_DELIMMAP | MDN_LOCALMAP | MDN_NAMEPREP | MDN_IDNCONV
In the case of using libmdnlite, it is equivalent the following specification (performing all except for MDN_LOCALCONV and MDN_UNASCHECK).
MDN_DELIMMAP | MDN_LOCALMAP | MDN_NAMEPREP | MDN_IDNCONV
If nothing is specified in actions
(that is, 0 is specified), the character string is simply copied.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_invalid_syntax,
mdn_invalid_name,
mdn_invalid_action,
mdn_buffer_overflow,
mdn_nomemory,
mdn_nofile,
mdn_prohibited.
If MDN_LOCALCONV is specified in using libmdnlite, mdn_invalid_action is returned.
mdn_decodename
mdn_result_t mdn_decodename(int actions, const char *from, char *to, size_t tolen);
Decodes a domain name. It converts the input character string
from and writes the result to the area specified by
to and tolen.
Specify the encoding behavior you wish mdn_decodename to
perform in actions. Specify such that the value is
yielded by logically OR'ing the flags that are listed below. The
specified behaviors are perfomed in the order given below.
-
MDN_IDNCONV - Converts UTF-8 character strings to a multilingual domain encoding (Punycode, RACE, etc.)
-
MDN_NAMEPREP - Checks whether the string is performed NAMEPREP correctly. If not performed correctly, undo IDN encoding to the string again.
-
MDN_UNASCHECK - Checks whether the string contained unassigned code point of NAMEPREP. If not performed correctly, undo IDN encoding to the string again.
-
MDN_LOCALCONV - Converts local encoding character strings (shift_JIS, Big5, etc.), to UTF-8. (It is available only in libmdn, not available in libmdnlite.)
Additionally, for the developer's convenience, we also provide
MDN_DECODE_APP
Usually applications will set this MDN_DECODE_APP to
actions.
In the case of using libmdn as library, this flag is equivalent the following specification.
MDN_IDNCONV | MDN_NAMEPREP | MDN_LOCALCONV
In the case of using libmdnlite, it is equivalent the following specification.
MDN_IDNCONV | MDN_NAMEPREP
If nothing is specified in actions
(that is, 0 is specified), the character string is simply copied.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_invalid_syntax,
mdn_invalid_name,
mdn_invalid_action,
mdn_buffer_overflow,
mdn_nomemory,
mdn_nofile,
mdn_prohibited.
If MDN_LOCALCONV is specified in using libmdnlite, mdn_invalid_action is returned.
mdn_localtoutf8
mdn_result_t mdn_localtoutf8(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_encodename(MDN_LOCAlCONV, from, to, tolen).
This function is available in libmdn. If using in libmdnlite, mdn_invalid_action is returned.
mdn_delimitermap
mdn_result_t mdn_delimitermap(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_encodename(MDN_DELIMMAP, from, to, tolen).
mdn_localmap
mdn_result_t mdn_localmap(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_encodename(MDN_LOCALMAP, from, to, tolen).
mdn_nameprep
mdn_result_t mdn_nameprep(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_encodename(MDN_NAMEPREP, from, to, tolen).
mdn_nameprepcheck
mdn_result_t mdn_nameprepcheck(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_decodename(MDN_NAMEPREP, from, to, tolen).
mdn_utf8toidn
mdn_result_t mdn_utf8toidn(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_encodename(MDN_IDNCONV, from, to, tolen).
mdn_idntoutf8
mdn_result_t mdn_idntoutf8(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_decodename(MDN_IDNCONV, from, to, tolen).
mdn_utf8tolocal
mdn_result_t mdn_utf8tolocal(const char *from, char *to, size_t tolen);
This entity is a cpp macro, which is equivalent to
mdn_decodename(MDN_LOCALCONV, from, to, tolen).
This function is available in libmdn. If using in libmdnlite, mdn_invalid_action is returned.
mdn_localtoidn
mdn_result_t mdn_localtoidn(const char *from, char *to, size_t tolen);
This entity is cpp macro, which is equivalent to
mdn_encodename(MDN_ENCODE_APP, from, to, tolen).
mdn_idntolocal
mdn_result_t mdn_idntolocal(const char *from, char *to, size_t tolen);
This entity is cpp macro, which is equivalent to
mdn_decodename(MDN_DECODE_APP, from, to, tolen).
brace module
The brace module performs conversion between UTF-8 and
the proposed
BRACE
encoding of multilingual domain names. However, because this encoding is already outdated encoding, be careful to use.
This module is implemented
as a low-order converter module,
and is not directly called by the application. When
converter module is requested in
association with BRACE encoding conversion, this module
is indirectly called.
This module provides the following API functions.
mdn__brace_open
mdn_result_t
mdn__brace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion context used for BRACE encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__brace_close
mdn_result_t
mdn__brace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion context used for BRACE encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__brace_convert
mdn_result_t
mdn__brace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion of BRACE and UTF-8 encoded character
strings. The from input character string is converted and
the result is written in the area specified by to and
tolen. When dir is
mdn_converter_l2u, BRACE strings are converted to UTF-8
encoding and when dir is mdn_converter_u2l, UTF-8 strings
are converted to BRACE encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
checker module
The checker module checks whether characters that cannot
be used in the domain name are included therein.
It currently supports the check schemes given below:
- NAMEPREP prohibited character checking
- NAMEPREP unassigned codepoint checking
- Checking by loading and following the descriptions in a file that defines prohibited characters and unassigned codepoints.
In addition, we also provide an API for registering additional check schemes.
The checker module uses the concept of a "check context."
First, before checking, a check context is created and the check
schemes to be used are registered to this context. During the actual
check processing, this check context is specified, rather than an
actual check scheme. This check context is of type
mdn_checker_t, which is defined as the opaque type given
below.
typedef struct mdn_checker *mdn_checker_t;
This module provides the following API functions.
mdn_checker_initialize
mdn_result_t mdn_checker_initialize(void)
Initializes the checker module. Always call this function before calling any other API function of the module.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_checker_create
mdn_result_t mdn_checker_create(mdn_checker_t *ctxp)
Creates an empty context for use in checking and stores it in the area
pointed to by ctxp. Since the returned context is empty, it
contains no check schemes. To add one or more check schemes, use
mdn_checker_add or
mdn_checker_addall.
When created by a context, the context reference count becomes 1.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_checker_destroy
void mdn_checker_destroy(mdn_checker_t ctx)
Decrements the reference count of the check context created by
mdn_checker_create by
one. If, as a result, the count becomes 0, it deletes the context, and
releases the allocated memory.
mdn_checker_incrref
void mdn_checker_incrref(mdn_checker_t ctx)
Increments the reference count of the check context created by
mdn_checker_create by
one.
mdn_checker_add
extern mdn_result_t mdn_checker_add(mdn_checker_t ctx, const char *name)
Adds the check scheme specified by name to the check
context created by
mdn_checker_create.
Multiple check schemes can be added to a single context.
The formats for the check scheme name are shown below:
-
MDN_CHECKER_PROHIBIT_PREFIX<nameprep-version> - Checks for the prohibited characters provided in NAMEPREP version <nameprep-version>.
-
MDN_CHECKER_UNASSIGNED_PREFIX<nameprep-version> - Checks for the unassigned codepoints provided in NAMEPREP version <nameprep-version>.
-
MDN_CHECKER_PROHIBIT_PREFIX fileset:<path> - Loads the prohibited character definitions in the file specified by <path>, and checks as therein described. For information on the file's description format, see the Set File Format section.
-
MDN_CHECKER_UNASSIGNED_PREFIX fileset:<path> - Loads the unassigned codepoint definitions from a file, and checks as therein described. For information on the file's description format, see the Set File Format section.
-
<prefix>
:<parameter> - Checks according to <prefix> the check scheme
registered by
mdn_checker_register. <parameter> is passed to the registered function create as an argument <parameter>.
MDN_CHECKER_PROHIBIT_PREFIX and
MDN_CHECKER_UNASSIGNED_PREFIX are cpp macros, and it is
the values from these macros that are actually used. In addition,
no whitespace can appear between the macro and its following
fileset or <nameprep-version>. Thus,
character string name is actually generated using the
method shown below:
sprintf(name, "%s%s", MDN_CHECKER_PROHIBIT_PREFIX, nameprep_version); sprintf(name, "%sfileset:%s", MDN_CHECKER_UNASSIGNED_PREFIX, file_path);
One of the following values is returned:
mdn_success,
mdn_invalid_name,
mdn_nomemory.
mdn_checker_addall
mdn_result_t mdn_checker_addall(mdn_checker_t ctx, const char **names, int nnames)
Other than the fact that mdn_checker_addall adds multiple
check schemes at once, it is identical to
mdn_checker_add. Each
element in the array names of length nnames is
registered as a check scheme. If all schemes are added successfully,
it returns mdn_success. If registration fails, only the
schemes described prior to the failed scheme are registered to context
ctx.
mdn_checker_lookup
mdn_result_t
mdn_checker_lookup(mdn_checker_t ctx, const char *utf8,
const char **found)
Checks the UTF-8 encoded character string utf8 using the
check schemes specified in ctx. If the character string
includes any prohibited characters or unassigned codepoints, the start
position of the offending character or codepoint is stored in
found. If no illegal characters are included, the function
returns NULL.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_checker_register
mdn_result_t
mdn_checker_register(const char *prefix,
mdn_checker_createproc_t create,
mdn_checker_destroyproc_t destroy,
mdn_checker_lookupproc_t lookup)
Registers a new check scheme. The check scheme name is specified in
prefix. The check scheme is specified using this name when
a check scheme is added to a context with
mdn_checker_add or
mdn_checker_addall.
create, destroy, and lookup specify
the respective function you wish to call when
mdn_checker_create,
mdn_checker_destroy, or
mdn_checker_lookup
processing is performed. Each of these functions must have the
following parameters and return values.
typedef mdn_result_t (*mdn_checker_createproc_t)
(const char *parameter, void **ctxp);
typedef void (*mdn_checker_destroyproc_t)
(void *ctx);
typedef mdn_result_t (*mdn_checker_lookupproc_t)
(void *ctx, const char *utf8, const char **found);
One of the following values is returned:
mdn_success,
mdn_nomemory.
converter module
converter module converts character string encoding (code
set). Because the MDN library uses UTF-8 character strings for
internal processing, this module performs bi-directional conversion
between the local encoding method and UTF-8.
Support is currently provided for the following encoding methods.
-
iconv()encoding method support
The iconv() function provides general code set conversion functions and encoding support. The encoding methods supported by iconv() are implementation-dependent; in that regard, refer to the documentation included with iconv() for information on which encoding is actually available. Moreover, this encoding method can be used in libmdn. it cannot be used in libmdnlite. - Various encodings of multilingual domain names
Many encodings are proposed for multilingual domain names, then MDN library supports many of these. About the encodings supported by library, refer to already outdated encodings. This encoding method can be used both in libmdn and libmdnlite.
The converter module is specially designed for encoding
conversion of domain names and is not suitable for general encoding
conversion. For example, Punycode, RACE, and DUDE
encoding provide special handling of the delimiting periods used in
domain names.
The converter module employs the "code conversion
context" concept. When performing bi-directional conversion between a
specific encoding method and UTF-8, first the code conversion context
of that encoding is created. For actual code conversion, the encoding
is not directly specified; instead this code conversion context is
specified. The code conversion context is mdn_converter_t
and is defined as the following opaque type.
typedef struct mdn_converter *mdn_converter_t;
This module provides the following API functions.
mdn_converter_initialize
mdn_result_t mdn_converter_initialize(void)
Initializes the module. This function is always called before calling other API functions of this module.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_converter_create
mdn_result_t
mdn_converter_create(const char *name, mdn_converter_t *ctxp,
int delayedopen)
Creates the code conversion context used for conversion between the local encoding specified by name and UTF-8, then initializes and stores it in the area specified by ctxp. When created by a context, the context reference count becomes 1.
As encoding schemes, the system currently provides Punycode,
RACE, and DUDE conversion functions. For
encoding methods other than those listed above, conversion is
performed using the iconv() utility provided with the
system. In such a case, when this function is invoked
iconv_open() is called. When delayedopen is
true, calling of iconv_open() is delayed until the
character string is actually converted.
In addition,
mdn_converter_register
can be also used to add new local encoding methods.
One of the following values is returned:
mdn_success,
mdn_invalid_name,
mdn_nomemory,
mdn_failure.
mdn_converter_destroy
void mdn_converter_destroy(mdn_converter_t ctx)
Decrements the reference count of the code conversion context created by
mdn_converter_create
by one. If, as a result, the count becomes 0, it deletes the context,
and releases the allocated memory.
mdn_converter_incrref
void mdn_converter_incrref(mdn_converter_t ctx)
Increments the reference count of the code conversion context created by
mdn_converter_create
by one.
mdn_converter_convert
mdn_result_t
mdn_converter_convert(mdn_converter_t ctx,
mdn_converter_dir_t dir, const char *from,
char *to, size_t tolen)
Uses the code conversion context created by
mdn_converter_create
to perform code conversion of character strings from and
stores the result in to. tolen is the length of
to. dir is used to specify the direction of
conversion.
-
mdn_converter_l2u - Converts from the encoding set in the context to UTF-8 encoding.
-
mdn_converter_u2l - Converts from UTF-8 to the encoding set in the context.
The set encoding is the encoding specified by
mdn_converter_create.
Unlike iconv(), when status-dependent encoding such as
ISO-2022-JP is used, the status that is in effect when
the function is called the first time is not maintained when this
function is called the next time. Conversion starts from the initial
status each time.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_invalid_name,
mdn_nomemory,
mdn_failure.
mdn_converter_localencoding
char * mdn_converter_localencoding(mdn_converter_t ctx)
Returns the local encoding name of the code conversion context ctx.
mdn_converter_isasciicompatible
int mdn_converter_isasciicompatible(mdn_converter_t ctx)
Returns whether the local encoding of the code conversion context ctx is ASCII-compatible. If the encoding is ASCII-compatible, 1 is returned; if not, 0 is returned.
ASCII-compatible encoding consists of only alphenumeric characters and hyphens, meaning it is not possible to differentiate between domain names encoded using this encoding and standard ASCII domain names. Specifically, Punycode encoding is of this type. These types of encoding are not generally used for local encoding by applications but are strong candidates for the encoding used to express domain names in the DNS protocol (because conventional DNS servers can be used without modification).
mdn_converter_addalias
mdn_result_t mdn_converter_addalias(const char *alias_name, const char *real_name)
Used to register the alias alias_name for the encoding name
real_name. Registered aliases can be specified in the
name argument of
mdn_converter_create.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_converter_aliasfile
mdn_result_t mdn_converter_aliasfile(const char *path)
Loads the file specified by the path variable and registers the alias in accordance with the contents of the file. The file path is a text file consisting of the following simple format.
Alias Formal name
Comment lines begin with #.
One of the following values is returned:
mdn_success,
mdn_nofile,
mdn_invalid_syntax,
mdn_nomemory.
mdn_converter_resetalias
mdn_result_t mdn_converter_resetalias(void)
Resets aliases registered using
mdn_converter_addalias
or
mdn_converter_aliasfile
to the initial default status (where no aliases are registered).
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_converter_register
mdn_result_t
mdn_converter_register(const char *name,
mdn_converter_openproc_t open,
mdn_converter_closeproc_t close,
mdn_converter_convertproc_t convert,
int ascii_compatible)
Adds the encoding conversion function between the name local encoding method and UTF-8. open, close, and convert are used as pointers to processing functions such as conversion. 1 specifies ascii_compatible local encoding, 0 that local encoding is not ASCII compatible.
One of the following values is returned:
mdn_success,
mdn_nomemory.
debug module
The debug module is a utility module for debug output.
This module provides the following API functions.
mdn_debug_hexstring
char * mdn_debug_hexstring(const char *s, int maxbytes)
Returns a hexidecimal character string of s
length. maxbytes indicates the maximum length expressed and
when s exceeds that length, ... is appended to
the string at that point.
The memory area allocated for the returned character string is used for the static variable held by this function and is in effect until the function is called the next time.
mdn_debug_xstring
char * mdn_debug_xstring(const char *s, int maxbytes)
Of the s character strings, returns in \x{HH}
format those character strings 128 bytes or
larger. maxbytes indicates the maximum length expressed and
when s exceeds this, ... is appended to the
string at that point.
The memory area allocated for the returned character string is used for the static variable held by this function and is in effect until the function is called the next time.
mdn_debug_hexdata
char * mdn_debug_hexdata(const char *s, int length, int maxlength)
Returns the length of byte row s in hexadecimal character strings.
maxbytes indicates the maximum length expressed
and when length exceeds this, ... is appended to the
string at that point.
The memory area allocated for the returned character string is used for the static variable held by this function and is in effect until the function is called the next time.
mdn_debug_hexdump
void mdn_debug_hexdump(const char *s, int length)
The standard error output is comprised of a hexidecimal dump of length of byte row s.
dn module
The dn module expands or compresses domain names in DNS
messages. This provides the functional equivalent of
res_comp and res_expand in the resolver
library.
This module was designed under the assumption that it would only be used by other modules in the libary.
When a domain name is compressed, context information of type mdn__dn_t is used,
as shown below:
#define MDN_DN_NPTRS 64
typedef struct {
const unsigned char *msg;
int cur;
int offset[MDN_DN_NPTRS];
} mdn__dn_t;
This module provides the following API functions.
mdn__dn_expand
mdn_result_t
mdn__dn_expand(const char *msg, size_t msglen,
const char *compressed, char *expanded,
size_t buflen, size_t *complenp)
Expands the compressed domain name in DNS message msg of length msglen and stores the result in expanded. buflen is the size of expanded. Also, the length of compressed is stored in *complenp.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_message.
mdn__dn_initcompress
void mdn__dn_initcompress(mdn__dn_t *ctx, const char *msg)
Initializes context information ctx for domain name compression. This function
must be called before calling mdn__dn_compress. msg is the leading address in a
DNS message where the compressed domain name is stored.
mdn__dn_compress
mdn_result_t
mdn__dn_compress(const char *name, char *sptr, size_t length,
mdn__dn_t *ctx, size_t *complenp)
Compresses the domain name indicated by name and stores it in the location indicated by sptr. length is the length of available space sptr. When compression is performed, the previously compressed domain name information in ctx is referenced. The length of the compressed domain name is placed in complenp and also the information necessary for compression is added to ctx.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_name.
delimitermap module
Normally, a period (.) is the only character used as a delimiter in domain
names. However, to enable characters other than a period to be used as
delimiters, this delimitermap module is used to map other characters to periods.
The delimitermap module uses the concept of a "delimiter map context." First,
before mapping, a delimiter map context is created and the characters to be used
as delimiters are registered. During the actual mapping process, this map
context is specified, rather than an actual mapping scheme. The mapping context
is of type mdn_delimitermap_t, which is defined as the opaque type given below.
typedef struct mdn_delimitermap *mdn_delimitermap_t;
This module provides the following API functions.
mdn_delimitermap_create
mdn_result_t mdn_delimitermap_create(mdn_delimitermap_t *ctxp)
Creates an empty delimiter map context for checking and stores it in the area
pointed to by ctxp. Since the returned context is empty, it contains no
delimiters. To add one or more delimiters, use
mdn_delimitermap_add or
mdn_delimitermap_addall.
When created by a context, the context reference count
becomes 1.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_delimitermap_destroy
void mdn_delimitermap_destroy(mdn_delimitermap_t ctx)
Decrements the reference count of the check context created by
mdn_delimitermap_create
by one. If, as a result, the count becomes 0, it deletes
the context, and releases the allocated memory.
mdn_delimitermap_incrref
void mdn_delimitermap_incrref(mdn_delimitermap_t ctx)
Increments the reference count of the context created by
mdn_delimitermap_create
by one.
mdn_delimitermap_add
extern mdn_result_t mdn_delimitermap_add(mdn_delimitermap_t ctx, unsigned long delimiter)
Adds UCS codepoint delimiter to the context created by
mdn_delimitermap_create
as a domain name delimiter.
However, to add a delimiter, this function must be called before
mdn_delimitermap_fix
is called. If this function is called after
mdn_delimitermap_fix has been called,
mdn_failure is returned.
This function returns one of the following values:
mdn_success,
mdn_nomemory,
mdn_invalid_codepoint,
mdn_failure.
mdn_delimitermap_addall
mdn_result_t mdn_delimitermap_addall(mdn_delimitermap_t ctx, const char **names, int nnames)
Other than the fact that mdn_delimitermap_addall adds delimiters at once, it is
identical to
mdn_delimitermap_add.
Each element in the array names of length
nnames is registered as a delimiter. If all delimiters are added successfully,
it returns mdn_success. If registration fails, only the delimiters described
prior to the failed scheme are registered to context ctx.
mdn_delimitermap_fix
void mdn_delimitermap_fix(mdn_delimitermap_t ctx)
Optimizes the arrangement of the data stored in the context. Once this function
is used,
mdn_delimitermap_add or
mdn_delimitermap_addall
cannot be used subsequently to register a delimiter.
On the other hand, this function must be called in order to perform mapping with
mdn_delimitermap_map.
mdn_delimitermap_map
mdn_result_t
mdn_delimitermap_map(mdn_delimitermap_t ctx, const char *from, char *to,
size_t tolen)
Applies the mapping specified in ctx to the UTF-8 encoded character string from.
It maps any delimiter registered in ctx to a period (.), and writes the result
to the area specified by to and tolen.
To use this function, you must first have called mdn_delimitermap_fix. If you
call this function without first having called mdn_delimitermap_fix, it returns
mdn_failure.
This function returns one of the following values:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_failure.
dude module
The dude module converts between the proposed
DUDE encoding multilingual domain
name encoding method and UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order
module for the converter module, and is not called directly from the
application. It is called indirectly when conversion to or from DUDE encoding is
requested of the converter module.
This module provides the following API functions.
mdn__dude_open
mdn_result_t
mdn__dude_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from DUDE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__dude_close
mdn_result_t
mdn__dude_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from DUDE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__dude_convert
mdn_result_t
mdn__dude_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
This performs bi-directional conversion between DUDE encoded character strings
and UTF-8 encoded character strings. It converts the input character string
from, and writes the result to the area specified by to and tolen. If dir is
mdn_converter_l2u, it converts from DUDE to UTF-8, if dir is mdn_converter_u2l,
it converts from UTF-8 to DUDE.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
filechecker module
The filechecker module is designed to load a file that defines characters that
cannot be used in domain names, and check the domain name according to those
definitions.
This module is packaged as a low-order module of the
checker module, and is not
called directly from the application. It is called indirectly when checking by
filecset is requested of the
checker module.
For information on the file's description format, see the Set File Format section.
This module provides the following API functions.
mdn__filechecker_create
mdn_result_t mdn__filechecker_create(const char *file, mdn_filechecker_t *ctxp)
Creates a single check file context. It loads file file, in which characters that cannot be used in domain names are defined, and adds them to the generated context.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_nofile,
mdn_invalid_syntax.
mdn__filechecker_destroy
void mdn__filechecker_destroy(mdn_filechecker_t ctx)
Deletes the context created by
mdn_filechecker_create, and releases the
allocated memory.
mdn__filechecker_lookup
mdn_result_t
mdn__filechecker_lookup(mdn_filechecker_t ctx, const char *utf8,
const char **found)
Checks the UTF-8 encoded character string utf8 using the check scheme specified
by ctx. If the character string includes any prohibited characters or unassigned
codepoints, the start position of the character or codepoint is stored in found.
If no illegal characters are included, the function returns NULL.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
filemapper module
The filemapper module is designed to load a file that defines the mapping rules
for each character in a domain name, and perform mapping according to those
definitions.
This module is packaged as a low-order module of the
mapper module, and is not
called directly from the application. It is called indirectly when checking by
filecmap is requested of the
mapper module.
For information on the file's description format, see the Map File Format section.
This module provides the following API functions.
mdn__filemapper_create
mdn_result_t mdn__filemapper_create(const char *file, mdn_filemapper_t *ctxp)
Creates a single map file context. It loads a file file that defines the mapping rules, and adds them to the generated check context.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_nofile,
mdn_invalid_syntax.
mdn__filemapper_destroy
void mdn__filemapper_destroy(mdn_filemapper_t ctx)
Deletes the context created by
mdn__filemapper_create,
and releases the
allocated memory.
mdn__filemapper_map
mdn_result_t
mdn__filemapper_map(mdn__filemapper_t ctx, const char *from,
char *to, size_t tolen);
Applies the mapping specified by ctx to the UTF-8 encoded character string from, and writes the result to the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
lace module
The lace module performs conversion between UTF-8 and the proposed
LACE
multilingual domain name encoding method. However, because this encoding is already outdated encoding, be careful to use.
This module is implemented as a
low-order converter module, and is not directly called by the application. When
the converter module is requested for conversion with LACE encoding, this module
is indirectly called.
This module provides the following API functions.
mdn__lace_open
mdn_result_t
mdn__lace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion context with LACE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__lace_close
mdn_result_t
mdn__lace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion context with LACE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__lace_convert
mdn_result_t
mdn__lace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Provides bi-directional conversion between LACE character strings and UTF-8
character strings. The from input character string is converted and the result
is written in the area specified by to and tolen. When dir is mdn_converter_l2u,
LACE encoding is converted to UTF-8 encoding. When it is mdn_converter_u2l,
UTF-8 encoding is converted to LACE encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
localencoding module
The localencoding module uses locale information to guess the encoding used by
the application.
This module provides the following API functions.
mdn_localencoding_name
const char * mdn_localencoding_name(void)
Guesses the type of encoding used by the application (the name passed to
mdn_converter_create())
and returns it based on the current locale information.
To guess the type of encoding, nl_langinfo() is used if it is available in the
the system and if not, setlocale() or environment variable information is
used. In the latter case, the correct encoding name may not be obtained.
When MDN_LOCAL_CODESET environment variable is defined in order to deal with situations in which the correct encoding cannot be guessed from the locale information or the application is operating using different encoding than that of the locale, this module returns the value of that variable as the encoding name regardless of the application locale.
log module
log module controls MDN library log output. A standard error output log is
written by default. It can, however, be changed to another output method by
registering the handler.
The log level can be set as well. The following five log levels are defined.
However, to get the log of mdn_log_level_dump level, needs to create MDN library with debug option.
About the detail, refer to mdn_log_dump.
enum {
mdn_log_level_fatal = 0,
mdn_log_level_error = 1,
mdn_log_level_warning = 2,
mdn_log_level_info = 3,
mdn_log_level_trace = 4,
mdn_log_level_dump = 5
};
This module provides the following API functions.
mdn_log_fatal
void mdn_log_fatal(const char *fmt, ...)
Outputs a fatal level log. This level is used when a fatal error occurs that
causes problems such as when program execution cannot be performed. Arguments
are specified using the same format as printf.
mdn_log_error
void mdn_log_error(const char *fmt, ...)
Outputs the error level log. This level is used when an error occurs that is not
fatal. Arguments are specified using the same format as printf.
mdn_log_warning
void mdn_log_warning(const char *fmt, ...)
Outputs a warning level log. This level is used to display a warning message.
Arguments are specified using the same format as printf.
mdn_log_info
void mdn_log_info(const char *fmt, ...)
Outputs info level log. This level is not used for errors but instead to output
other potentially useful information. Arguments are specified using the same
format as printf.
mdn_log_trace
void mdn_log_trace(const char *fmt, ...)
Outputs the trace level log. This level is used to output API function trace
information. Generally, this log does not need to be recorded for purposes other
than debugging the library. The arguments are specified using the same format as
printf.
mdn_log_dump
void mdn_log_dump(const char *fmt, ...)
Outputs the dump level log. This level is used to output additional packet data
dump for debugging. Generally, this level of log does not need to be recorded
for purposes other than debugging the library. The arguments are specified using
the same format as for printf.
dump level is created for debug internal of library, then if correctly set log level by mdn_log_setlevel and so on, usually not output.
To output, specifies --enable-debug option in executing configure.
mdn_log_setlevel
void mdn_log_setlevel(int level)
Sets the level of log output. Logs higher than the set level are not output.
When the log level is not specified with this function, the integer value set to
the MDN_LOG_LEVEL environment variable is used.
mdn_log_getlevel
int mdn_log_getlevel(void)
Obtains and returns the integer value for the current level of log output.
mdn_log_setproc
void mdn_log_setproc(mdn_log_proc_t proc)
Used to set the log output handler. proc is a pointer to the handler function.
When the handler is not specified or NULL is specified for proc, a standard
error log is output.
The mdn_log_proc_t handler type is defined as follows.
typedef void (*mdn_log_proc_t)(int level, const char *msg);
The log level is passed to level and the message character string that should be displayed is passed to msg.
mace module
The mace module converts between the proposed
MACE encoding multilingual domain name encoding method and
UTF-8 encoding. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the
converter module, and is not
called directly by the application. It is called indirectly when
conversion to or from MACE encoding is requested of
the converter module.
This module provides the following API functions.
mdn__mace_open
mdn_result_t
mdn__mace_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from MACE encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__mace_close
mdn_result_t
mdn__mace_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from MACE encoding. Actually, this does
not do anything. Always returns mdn_success.
mdn__mace_convert
mdn_result_t
mdn__mace_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between MACE encoded character
strings and UTF-8 encoded character strings. It converts the input
character string from and writes the result to the area
specified by to and tolen. If dir is
mdn_converter_l2u, it converts the character string from
MACE encoding to UTF-8 encoding; if dir is
mdn_converter_u2l, it converts the character string from
UTF-8 encoding to AMC-ACE-M encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
mapper module
The mapper module is designed to perform mapping of characters in domain names.
The following mapping schemes are currently supported:
- NAMEPREP mapping
- Loads a file that defines the mapping rules, and maps according to those rules.
An API is also provided to register additional mapping schemes.
The mapper module uses the concept of a "map context." First, before mapping, a
map context is created and the mapping schemes to be used are registered to this
context. During the actual mapping process, this map context is specified,
rather than an actual mapping scheme. The mapping context is of type
mdn_mapper_t, which is defined as the opaque type given below.
typedef struct mdn_mapper *mdn_mapper_t;
This module provides the following API functions.
mdn_mapper_initialize
mdn_result_t mdn_mapper_initialize(void)
Initializes the module. Always call this function before calling any other API function of this module.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_mapper_create
mdn_result_t mdn_mapper_create(mdn_mapper_t *ctxp)
Creates an empty context for mapping and stores it in the area pointed to by
ctxp. Since the returned context is empty, it contains no mapping schemes. To
add one or more mapping schemes, use
mdn_mapper_add or
mdn_mapper_addall. When
created by a context, the context reference count becomes 1.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_mapper_destroy
void mdn_mapper_destroy(mdn_mapper_t ctx)
Decrements the reference count of the context created by
mdn_mapper_create by
one. If, as a result, the count becomes 0, it deletes the context, and releases
the allocated memory.
mdn_mapper_incrref
void mdn_mapper_incrref(mdn_mapper_t ctx)
Increments the reference count of the context created by
mdn_mapper_create by one.
mdn_mapper_add
extern mdn_result_t mdn_mapper_add(mdn_mapper_t ctx, const char *name)
Adds the mapping scheme specified by name to the context created by
mdn_mapper_create.
Multiple mapping schemes can be added to a single context.
The format of the mapping scheme name is as shown below:
- <nameprep-version>
- NAMEPREP version <nameprep-version> mapping rules.
-
filemap:<path> - Loads the mapping rules in the file specified by <path>, and checks as described in this file. For information on the file's description format, see the Map File Format section.
-
<prefix>
:<parameter> - Checks according to the mapping scheme <prefix>
registered by
mdn_mapper_register. <parameter> is passed to the registered function create as an argument <parameter>.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_mapper_addall
mdn_result_t mdn_mapper_addall(mdn_mapper_t ctx, const char **names, int nnames)
Other than the fact that mdn_mapper_addall adds multiple mapping schemes at
once, it is identical to
mdn_mapper_add. Each element in the array names of
length nnames is registered as a mapping scheme. If all schemes are added
successfully, it returns mdn_success. If registration fails, only the schemes
described prior to the failed scheme are registered to context ctx.
mdn_mapper_map
mdn_result_t
mdn_mapper_map(mdn_mapper_t ctx, const char *from, char *to,
size_t tolen)
Applies the mapping scheme specified by ctx to the UTF-8 encoded character
string from, and writes the result to the area specified by to and tolen. If ctx
contains multiple mapping schemes, they are applied in the order added by
mdn_mapper_add.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_mapper_register
mdn_result_t
mdn_mapper_register(const char *prefix,
mdn_mapper_createproc_t create,
mdn_mapper_destroyproc_t destroy,
mdn_mapper_lookupproc_t lookup)
Registers a new mapping scheme. The mapping scheme name is specified in prefix.
The mapping method is specified by this name when a mapping scheme is added to
the context with
mdn_mapper_add or
mdn_mapper_addall.
create, destroy, and lookup specify the respective functions you wish to call
when
mdn_mapper_create,
mdn_mapper_destroy, or
mdn_mapper_map processing is
performed. Each of these functions must have the following parameters and return
values.
typedef mdn_result_t (*mdn_mapper_createproc_t)
(const char *parameter, void **ctxp);
typedef void (*mdn_mapper_destroyproc_t)
(void *ctx);
typedef mdn_result_t (*mdn_mapper_mapproc_t)
(void *ctx, const char *utf8, const char *from, char *to,
size_t tolen);
One of the following values is returned:
mdn_success,
mdn_nomemory.
mapselector module
As does the mapper module, the mapselector module maps characters in domain
names. mapselector expands mapper so that it can be used with the different
mapping rules needed for the top level domain of a domain name.
The mapselector module uses the concept of a "map selection context." First,
before mapping, a map context is created and the mapping schemes to be used are
registered to this context. During the actual mapping process, this map context
is specified, rather than an actual mapping scheme. The mapping context is of
type mdn_mapselector_t, which is defined as the opaque type given below.
typedef struct mdn_mapselector *mdn_mapselector_t;
This module provides the following API functions.
mdn_mapselector_initialize
mdn_result_t mdn_mapselector_initialize(void)
Initializes the module. Always call this function before calling any other API function of this module.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_mapselector_create
mdn_result_t mdn_mapselector_create(mdn_mapselector_t *ctxp)
Creates an empty context for map selection and stores it in the area pointed to
by ctxp. Since the returned context is empty, it contains no mapping schemes. To
add one or more mapping schemes, use
mdn_mapselector_add or
mdn_mapselector_addall. When created by a context, the context reference count
becomes 1.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_mapselector_destroy
void mdn_mapselector_destroy(mdn_mapselector_t ctx)
Decrements the reference count of the map context created by
mdn_mapselector_create
by one. If, as a result, the count becomes 0, it deletes
the context, and releases the allocated memory.
mdn_mapselector_incrref
void mdn_mapselector_incrref(mdn_mapselector_t ctx)
Increments the reference count of the context created by
mdn_mapselector_create
by one.
mdn_mapselector_mapper
mdn_mapper_t mdn_mapselector_mapper(mdn_mapselector_t ctx, const char *tld)
The map selection context ctx stores and manages the mapping rules for each top
level domain in a single mapper module context. ctx maintains this function, and
extracts the mapper context for the corresponding top level domain tld.
The reference count of the extracted context becomes 2. When you have finished
using the extracted context, always be sure to call
mdn_mapper_destroy to
decrement the reference count.
mdn_mapselector_add
extern mdn_result_t mdn_mapselector_add(mdn_mapselector_t ctx, const char *tld, const char *name)
Adds name as a mapping scheme for the tld domain name of a top level domain to
the context created by
mdn_mapselector_create. Multiple mapping schemes can be
added to each top level domain in a single context.
tld specifies the top level domain name, like .jp or .tw. (The leading dot (.) may be omitted.)
In addition, by specifying a dot (.) in tld, one can add default mapping rules
for top level domains whose mapping rules have not been defined. In a similar
manner, by specifying a dash (-), one can add mapping rules suitable for domain
names (which exclude the dot (.)) that do not have a top level domain.
The format of mapping scheme name is the same as that for
mdn_mapper_map, and
mapping schemes registered with
mdn_mapper_register can also be specified here.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_mapselector_addall
mdn_result_t
mdn_mapselector_addall(mdn_mapselector_t ctx, const char *tld,
const char **names, int nnames)
Other than the fact that mdn_mapselector_addall adds multiple mapping schemes at
once, it is identical to
mdn_mapselector_add. Each element in the array names
of length nnames is registered as a mapping scheme. If all schemes are added
successfully, it returns mdn_success. If registration fails, only the schemes
described prior to the failed scheme are registered to context ctx.
mdn_mapselector_map
mdn_result_t
mdn_mapselector_map(mdn_mapselector_t ctx, const char *from, char *to,
size_t tolen)
Applies the mapping scheme specified with the ctx corresponding to the top level
domain of the domain name from to its UTF-8 encoded domain name character
string, and writes the result to the area specified by to and tolen. If ctx
contains multiple mapping schemes for that top level domain, they are applied in
the order added by mdn_mapselector_add.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_buffer_overflow,
mdn_invalid_encoding.
msgheader module
msgheader module analyses and assembles the DNS message header.
Analyzed header information is placed in the following structure. Since each field corresponds to a field of DNS message header, the explanation is omitted here.
typedef struct mdn_msgheader {
unsigned int id;
int qr;
int opcode;
int flags;
int rcode;
unsigned int qdcount;
unsigned int ancount;
unsigned int nscount;
unsigned int arcount;
} mdn_msgheader_t;
This module provides the following API functions.
mdn_msgheader_parse
mdn_result_t
mdn_msgheader_parse(const char *msg, size_t msglen,
mdn_msgheader_t *parsed)
Analyzes the DNS message headers indicated by msg and msglen and stores the information in the structure indicated by parsed.
One of the following values is returned:
mdn_success,
mdn_invalid_message.
mdn_msgheader_unparse
mdn_result_t
mdn_msgheader_unparse(mdn_msgheader_t *parsed,
char *msg, size_t msglen)
This function performs reverse processing of
mdn_msgheader_parse, in which the
DNS message header is structured from the structure data specified by parsed ,
after which it is stored in the area specified by msg and msglen.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow.
mdn_msgheader_getid
unsigned int mdn_msgheader_getid(const char *msg)
Extracts the ID from the DNS message specified by msg and returns it. This function is only useful for extracting the ID without analyzing the entire header. Since this function assumes the data indicated by msg is longer than the DNS message header length, always call the function after confirmation at the calling side.
mdn_msgheader_setid
void mdn_msgheader_setid(char *msg, unsigned int id)
Sets the ID specified by id in the DNS message specified by msg. Since this function also assumes that the data indicated by msg is longer than the DNS message header length, always call the function after confirmation at the calling side.
msgtrans module
The msgtrans module provides a large portion of DNS message conversion
processing performed by the DNS proxy server. This module is implemented as a
high-order module for many other modules including the
converter module and
normalizer module.
Message conversion processing by the DNS proxy server is briefly explained below.
Conversion of a message from a client to the DNS server is as follows.
- Request message received from client is analyzed and encoding at the client side are determined.
- Using the determination result, the encoding is converted to UTF-8.
- Normalization processing is performed.
- The encoding is converted from UTF-8 to the encoding used by the DNS server side.
- The above processing is performed on all domain names included in the message and the conversion results are collectively placed in the DNS message format and then sent to the DNS server.
Conversion of messages from the DNS server to the client is as follows.
- The reply message received from the DNS server is analyzed and removal of ZLD and conversion to UTF-8 encoding are performed on all domain names included in the message.
- Encoding is converted to the client side encoding and ZLD are added.
- The conversion results are collectively placed in the DNS message format and then sent to the client.
This module provides the following API functions.
mdn_msgtrans_translate
mdn_result_t
mdn_msgtrans_translate(mdn_resconf_t resconf,
const char *msg, size_t msglen,
char *outbuf, size_t outbufsize,
size_t *outmsglenp)
Converts the DNS messages specified by msg and msglen according to the conversion parameter resconf and stores the result in the area indicated by outbuf and outbufsize. The message length of the conversion result is stored in outmsglenp.
One of the following values is returned:
mdn_success,
mdn_invalid_message,
mdn_invalid_encoding,
mdn_buffer_overflow.
nameprep module
The nameprep module is designed to normalize domain names according to the
descriptions provided in NAMEPREP.
The following NAMEPREP versions are currently supported:
-
nameprep-03 -
nameprep-05 -
nameprep-06 -
nameprep-07
The nameprep module uses the concept of a "NAMEPREP context." First, before
normalization, a NAMEPREP context is created and the versions to be used are
registered to this context. During the actual normalization process, the context
is specified, rather than an actual NAMEPREP version. The NAMEPREP context is of
type mdn_nameprep_t, which is defined as the opaque type given below.
typedef struct mdn_nameprep *mdn_nameprep_t;
This module provides the following API functions.
mdn_nameprep_create
mdn_result_t mdn_nameprep_create(const char *version, mdn_nameprep_t *ctxp)
Creates the NAMEPREP context of the specified version version and stores it in the area pointed to by ctxp.
One of the following values is returned:
mdn_success,
mdn_notfound.
mdn_nameprep_destroy
void mdn_nameprep_destroy(mdn_nameprep_t ctx)
Deletes the NAMEPREP context created by
mdn_nameprep_create, and releases the
allocated memory.
mdn_nameprep_map
mdn_result_t
mdn_nameprep_map(mdn_nameprep_t ctx, const char *from, char *to,
size_t tolen)
Applies the mapping scheme specified by ctx to the UTF-8 encoded character string from, and writes the result to the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_nameprep_isprohibited
mdn_result_t
mdn_nameprep_isprohibited(mdn_nameprep_t ctx, const char *utf8,
const char **found)
Checks the UTF-8 encoded character string utf8 using the check scheme specified by ctx. If the character string includes any characters whose use is prohibited, the offending character's start position is stored in found. If no prohibited characters are included, the function returns NULL.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding.
mdn_nameprep_isunassigned
mdn_result_t
mdn_nameprep_isunassigned(mdn_nameprep_t ctx, const char *utf8,
const char **found)
Checks the UTF-8 encoded character string utf8 using the check scheme specified by ctx. If the character string includes any unassigned codepoints, the offending codepoint's start position is stored in found. If no unassigned codepoints are included, the function returns NULL.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding.
normalizer module
normalizer module normalizes character string. The following normalization
methods are currently provided.
However, it is due to unsupport the methods marked (*) in the future release.
-
ascii-uppercase(*)
Converts ASCII lowercase to uppercase -
ascii-lowercase(*)
Converts ASCII uppercase to lowercase -
unicode-uppercase(*)
Converts lowercase to uppercase in accordance with the lowercase/uppercase mapping described in Case Mappings that prescribes character properties of Unicode. -
unicode-lowercase(*)
Converts uppercase to lowercase in accordance with the same above document. -
unicode-foldcase(*)
Converts when comparing without distinguishing between uppercase and lowercase in accordance with the same above document. -
unicode-form-c(*)Normaliztion form Cby the latest version of Unicode which mDNkit supports. (AboutNormaliztion form C, refer to Unicode Normalization Forms.) -
unicode-form-kcNormaliztion form KCby the latest version of Unicode which mDNkit supports. (AboutNormaliztion form KC, refer to Unicode Normalization Forms.) -
unicode-form-d(*)Normaliztion form Dby the latest version of Unicode which mDNkit supports. (AboutNormaliztion form D, refer to Unicode Normalization Forms.) -
unicode-form-kd(*)Normaliztion form KDby the latest version of Unicode which mDNkit supports. (AboutNormaliztion form KD, refer to Unicode Normalization Forms.) -
unicode-form-c/3.0.1(*)
Unicode normalization form C by Unicode version 3.0.1. -
unicode-form-kc/3.0.1
Unicode normalization form KC by Unicode version 3.0.1. -
unicode-form-c/3.1.0(*)
Unicode normalization form C by Unicode version 3.1.0. -
unicode-form-kc/3.1.0
Unicode normalization form KC by Unicode version 3.1.0. -
unicode-form-d/3.1.0(*)
Unicode normalization form D by Unicode version 3.1.0. -
unicode-form-kd/3.1.0(*)
Unicode normalization form KD by Unicode version 3.1.0. -
nameprep-03
Alias ofunicode-form-kc/3.0.1. -
nameprep-05
Alias ofunicode-form-kc/3.1.0. -
nameprep-06
Alias ofunicode-form-kc/3.1.0. As same as nameprep-05. -
nameprep-07
Alias ofunicode-form-kc/3.1.0. As same as nameprep-05.
More than one normalization method can be used and they are applied in the order they were specified. At the same time, the APIs to regist adding another new normalization is also prepared.
normalizer module uses the concept "normalization context". Prior to
normalization, a normalization context is created and the normalization method
to be used is registered in the context. For actual normalization procesesing,
not the normalization method but this normalization context is specified. The
type of normalization context is mdn_normalizer_t type and defined as the
following opaque type.
typedef struct mdn_normalizer *mdn_normalizer_t;
This module provides the following API functions.
mdn_normalizer_initialize
mdn_result_t mdn_normalizer_initialize(void)
Initializes module. Make sure to call this function before calling other API function of this module.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_normalizer_create
mdn_result_t mdn_normalizer_create(mdn_normalizer_t *ctxp)
Creates an empty context for normalization and stores it in the area pointed to
by ctxp. Since the returned context is empty, it contains no normalization
schemes. To add one or more normalization schemes, use
mdn_normalizer_add or
mdn_normalizer_addall. When created by the context, the context reference count
becomes 1.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_normalizer_destroy
void mdn_normalizer_destroy(mdn_normalizer_t ctx)
Decrements the reference count of the normalization context created by
mdn_normalizer_create by one. If, as a result, the count becomes 0, it deletes
the context, and releases the allocated memory.
mdn__nomalizer_incrref
void mdn_normalizer_incrref(mdn_normalizer_t ctx)
Increments the reference count of the normalization context created by
mdn_normalizer_create by one.
mdn_normalizer_add
mdn_result_t mdn_normalizer_add(mdn_normalizer_t ctx, const char *scheme_name)
Adds the normalization method specified by scheme_name in the normalization
context created by
mdn_normalizer_create. More than one normalization method
can be specified in one context.
One of the following values is returned:
mdn_success,
mdn_invalid_name,
mdn_nomemory.
mdn_normalizer_addall
mdn_result_t
mdn_normalizer_addall(mdn_normalizer_t ctx, const char **scheme_names,
int nschemes)
Other than the fact that mdn_normalizer_addall adds multiple normalization
schemes at once, it is identical to
mdn_normalizer_add. Each element in the
array scheme_names of length nschemes is registered as a normalization scheme.
If all schemes are added successfully, it returns mdn_success. If registration
fails, only the schemes described prior to the failed scheme are registered to
context ctx.
mdn_normalizer_normalize
mdn_result_t
mdn_normalizer_normalize(mdn_normalizer_t ctx,
const char *from, char *to, size_t tolen)
Applies the normalization method specified by ctx to the character strings
encoded by UTF-8 from and writes the result in the area specified by to and
tolen. When more than one normalization method is included in ctx, they are
applied in the order they were added by mdn_normalizer_add.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_nomemory.
mdn_normalizer_register
mdn_result_t
mdn_normalizer_register(const char *scheme_name,
mdn_normalizer_proc_t proc)
New normalization methods are registered in scheme_name. proc is a pointer to the processing function of that normalization method.
One of the following values is returned:
mdn_success,
mdn_nomemory.
race module
The race module performs conversion between UTF-8 and the proposed
RACE
multilingual domain name method.
This module is implemented as a low-order
module of converter module and is not directly called by the application. When
converter module is requested for conversion with RACE encoding, this module is
indirectly called.
This module provides the following API functions.
mdn__race_open
mdn_result_t
mdn__race_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion context with RACE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__race_close
mdn_result_t
mdn__race_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion context with RACE encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__race_convert
mdn_result_t
mdn__race_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
Performs bi-directional conversion between RACE-encoded and UTF-8 encoded
character strings. Converts the from input character string and writes the
result in the area specified by to and tolen. When dir is mdn_converter_l2u,
RACE encoding is converted to UTF-8 encoding. When it is mdn_converter_u2l,
UTF-8 encoding is converted to RACE encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
res module
The res module provides row level APIs used when multilingual domain names are
processed at the client side (by an application) i.e.
when domain name encoding conversion or normalization is performed. This module
is designed on the assumption that it will be used together with
resconf module,
which is explained below.
Using APIs provided by the module, it is not necessary to directly call
converter module or
normalizer module function.
In addition, in the case of setting environment variable MDN_DISABLE, even if using the functions for string conversion which are cited in the following, conversion of strings is not performed, but returned the result as the original string.
In the case of performing conversion of strings in setting MDN_DISABLE environment, or wanting to assure constant performance whether setting MDN_DISABLE or not, mdn_res_enable must be used on ahead.
This module provides the following API functions.
mdn_res_enable
void mdn_res_enable(int on_off);
Usually, in the case of defining environment variable MDN_DISABLE, process of domain name conversion is not performed, but the result as the original string is returned, however this function can overrides the setting.
Whether MDN_DISABLE is set or not, if this function is used with setting a value other than 0 for on_off, conversion of domain name become to perform subsequently. If setting 0, contrary conversion of domain name is not performed, but the result as the original string is returned.
mdn_res_nameconv
mdn_result_t
mdn_res_nameconv(mdn_resconf_t ctx, const char *insn,
const char *from, char *to, size_t tolen)
Performs conversion and checking on a multilingual domain name in the character string from, and stores the result in the area specified by to and tolen. The conversion and checking is performed according to configuration context ctx.
Specifically, the kind of conversions and checks that are performed, and the order in which they are performed, is specified by the character string insn. The conversion and check methods are all expressed as one character as shown below. The methods corresponding to these characters are evaluated from beginning to end in the order set in the character string insn.
-
l - Convert from local encoding to UTF-8.
(It is available only in libmdn, not available in libmdnlite.) -
L - Convert from UTF-8 to local encoding.
(It is available only in libmdn, not available in libmdnlite.) -
d - Perform delimiter mapping.
-
M - Apply local mapping.
-
m - Perform mapping.
-
n - Perform normalization.
-
N - Perform NAMEPREP (mapping, normalize, check prohibit characters).
Equalize with `
mnp'. -
p - Check for prohibited characters.
-
u - Check assigned codepoints.
-
!m - Check whether the string performed mapping correctly. If not correctly, convert IDN encoding.
-
!n - Check whether the string performed normalization correctly. If not correctly, convert IDN encoding.
-
!p - Check whether the string contained prohibit character. If contained, convert IDN encoding.
-
!N - Check whether the string performed NAMEPREP correctly (which is the string performed mapping, normalization, and not contained prohibit character). If not correctly, convert IDN encoding.
-
!u - Check whether the string contained unassigned code point. If contained, convert IDN encoding.
-
I - Convert from UTF-8 to IDN encoding.
-
i - Convert from IDN encoding to UTF-8 encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_invalid_name,
mdn_invalid_action,
mdn_invalid_nomemory,
mdn_invalid_nomapping,
mdn_invalid_prohibited,
mdn_failure.
In using libmdnlite, give insn includeing l or L to mdn_res_nameconv(), mdn_invalid_action is returned.
mdn_res_localtoucs
mdn_result_t
mdn_res_localtoucs(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Converts the character string from local encoding to UTF-8. It is equivalent to the following process:
mdn_res_nameconv(ctx, "l", from, to, tolen)
This function is available in libmdn. If using in libmdnlite, mdn_invalid_action is returned.
mdn_res_ucstolocal
mdn_result_t
mdn_res_ucstolocal(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Converts a character string from UTF-8 to local encoding. It is equivalent to the following process:
mdn_res_nameconv(ctx, "L", from, to, tolen)
This function is available in libmdn. If using in libmdnlite, mdn_invalid_action is returned.
mdn_res_delimitermap
mdn_result_t
mdn_res_delimitermap(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Performs delimiter mapping on a character string. It is equivalent to the following process:
mdn_res_nameconv(ctx, "d", from, to, tolen)
mdn_res_localmap
mdn_result_t
mdn_res_localmap(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Applies local mapping to a character string. It is equivalent to the following process:
mdn_res_nameconv(ctx, "M", from, to, tolen)
mdn_res_map
mdn_result_t
mdn_res_map(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Performs mapping on a character string. It is equivalent to the following process:
mdn_res_nameconv(ctx, "m", from, to, tolen)
mdn_res_normalize
mdn_result_t
mdn_res_normalize(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Performs normalization on a character string. It is equivalent to the following process:
mdn_res_nameconv(ctx, "n", from, to, tolen)
mdn_res_prohibitcheck
mdn_result_t
mdn_res_prohibitcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Checks a character string for prohibited characters. It is equivalent to the following process:
mdn_res_nameconv(ctx, "p", from, to, tolen)
mdn_res_nameprep
mdn_result_t
mdn_res_nameprep(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Perform NAMEPREP for strings. This is equivalent to the following process.
mdn_res_nameconv(ctx, "N", from, to, tolen)
mdn_res_nameprepcheck
mdn_result_t
mdn_res_nameprepcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Check whether the string performed NAMEPREP correctly (which is the string performed mapping, normalization, and not contained prohibit character). If not performed correctly, convert IDN encoding. This is equivalent to the following process.
mdn_res_nameconv(ctx, "!N", from, to, tolen)
mdn_res_unassignedcheck
mdn_result_t
mdn_res_unassignedcheck(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen)
Checks a character string for unassigned codepoints. It is equivalent to the following process:
mdn_res_nameconv(ctx, "u", from, to, tolen)
mdn_res_ucstodns
mdn_result_t
mdn_res_ucstodns(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen);
Converts a character string from UTF-8 to IDN encoding. It is equivalent to the following process:
mdn_res_nameconv(ctx, "I", from, to, tolen)
mdn_res_dnstoucs
mdn_result_t
mdn_res_dnstoucs(mdn_resconf_t ctx, const char *from, char *to,
size_t tolen);
Converts a character string from IDN encoding to UTF-8. It is equivalent to the following process:
mdn_res_nameconv(ctx, "i", from, to, tolen)
resconf module
The resconf module loads the mDNkit configuration file referenced when a
multilingual domain name is processed at the client side (by MDN library
or application) and executes initialization in accordance with the settings
described in the file. It also provides a function to extract the setting
information.
The resconf module uses the concept of a "configuration context." The settings
described in a configuration file are stored in this configuration context,
which can then be used as an argument to call API functions to extract the set
values. The NAMEPREP context is of type mdn_resconf_t, which is defined as the
opaque type given below.
typedef struct mdn_resconf *mdn_resconf_t;
This module can be used as a single module but it is designed so that by
combining it with res module multilingual domain names can easily be processed
at the client side.
This module provides the following API functions.
mdn_resconf_initialize
mdn_result_t mdn_resconf_initialize(void)
Executes initialization required when processing multilingual domain names. Always call this function before calling other API functions of this module. Since this function initializes all other modules used by this module, it is not necessary to call another initialization function.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_resconf_create
mdn_result_t mdn_resconf_create(mdn_resconf_t *ctxp)
Creates and initializes a configuration context and stores it in the area
pointed to by ctxp. In its initial state, the contents of the configuration file
are not loaded. To do so,
mdn_resconf_loadfile must be executed.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_resconf_destroy
void mdn_resconf_destroy(mdn_resconf_t ctx)
mdn_resconf_loadfile
mdn_result_t mdn_resconf_loadfile(mdn_resconf_t ctx, const char *file)
Loads the contents of the mDNkit configuration file specified by file, and stores the setting contents in configuration context ctx. When file is NULL, it loads the contents of the default configuration file.
If another configuration is loaded into a context in which a configuration file has already been loaded, the previous configuration file contents stored in the configuration context are deleted and replaced with the newly loaded configuration file contents.
One of the following values is returned:
mdn_success,
mdn_nofile,
mdn_invalid_syntax,
mdn_invalid_name,
mdn_nomemory.
mdn_resconf_defaultfile
char * mdn_resconf_defaultfile(void)
Returns the pathname of the default configuration file. This is determined by the settings set when mDNkit is compiled. The default path is as follows:
/usr/local/etc/mdn.conf
彫ヌ彫ケ庁」
mdn_resconf_getidnconverter
mdn_converter_t mdn_resconf_getidnconverter(mdn_resconf_t ctx)
Based on the information in configuration context ctx, this function returns the code conversion context for performing character code conversion between IDN encoding and UTF-8. It returns NULL if an IDN encoding is not specified in the context.
For information on the code conversion context, refer to the converter module
section.
mdn_resconf_getlocalconverter
mdn_converter_t mdn_resconf_getlocalconverter(mdn_resconf_t ctx)
Based on the information in configuration context ctx, this function returns the code conversion context for performing character code conversion between local encoding and UTF-8. NULL is returned if the local encoding cannot be determined.
For information on the code conversion context, refer to the
converter module section.
mdn_resconf_getmapper
mdn_mapper_t mdn_resconf_getmapper(mdn_resconf_t ctx)
Based on information in information in configuration context ctx, this function returns the map context for performing normalization. It returns NULL if a mapping scheme is not specified in the context.
For information on the map context, refer to the mapper module section.
mdn_resconf_getnormalizer
mdn_normalizer_t mdn_resconf_getnormalizer(mdn_resconf_t ctx)
Based on information in configuration context ctx, this function returns the
normalization context for performing normalization. It returns NULL if a
normalization scheme is not specified in the context.
For information on the normalization context, refer to the
normalizer module section.
mdn_resconf_getprohibit
mdn_checker_t mdn_resconf_getprohibit(mdn_resconf_t ctx)
Based on information in configuration context ctx, this function returns the
check context for performing prohibited character check processing. It returns
NULL if a prohibited character check scheme is not specified in the context.
For information on the check context, refer to the
checker module section.
mdn_resconf_getunassigned
mdn_checker_t mdn_resconf_getunassigned(mdn_resconf_t ctx)
Based on information in configuration context ctx, this function returns the
normalization context for performing unassigned codepoint check processing. It
returns NULL if an unassigned codepoint check scheme is not specified in the
context.
For information on the check context, refer to the checker module section.
mdn_resconf_getdelimitermap
mdn_delimitermap_t mdn_resconf_getdelimitermap(mdn_resconf_t ctx)
Based on information in configuration context ctx, this function returns the delimiter map context for performing delimiter mapping. It returns NULL if no delimiters are specified in the context.
For information on the delimiter map context, refer to the
delimitermap module section.
mdn_resconf_getmapselector
mdn_mapselector_t mdn_resconf_getmapselector(mdn_resconf_t ctx)
Based on information in configuration context ctx, this function returns the map
selection context for performing local mapping corresponding to the top level
domain. It returns NULL if no local mapping scheme is specified in the context.
For information on the map selection context, refer to the
mapselector module section.
mdn_resconf_setidnconverter
mdn_result_t
mdn_resconf_setidnconverter(mdn_resconf_t ctx,
mdn_converter_t idn_converter)
Based on information in code conversion context idn_converter, this function
sets the conversion scheme for performing character code conversion between IDN
encoding and UTF-8 into configuration context ctx. If NULL is passed to
idn_converter, no conversion scheme is set.
For information on the code conversion context, refer to the
converter module section.
mdn_resconf_setlocalconverter
mdn_result_t
mdn_resconf_setlocalconverter(mdn_resconf_t ctx,
mdn_converter_t local_converter)
Based on information in code conversion context local_converter, this function
sets the conversion scheme for performing character code conversion between
local encoding and UTF-8 into configuration context ctx. If NULL is passed to
local_converter, no conversion scheme is set.
For information on the code conversion context, refer to the
converter module section.
mdn_resconf_setmapper
mdn_result_t mdn_resconf_setmapper(mdn_resconf_t ctx, mdn_mapper_t mapper)
Based on information in map context mapper, this function sets the scheme for
performing mapping into configuration context ctx. If NULL is passed to mapper,
no normalization scheme is set.
For information on the map context, refer to the
mapper module section.
mdn_resconf_setnormalizer
mdn_result_t
mdn_resconf_setnormalizer(mdn_resconf_t ctx,
mdn_normalizer_t normalizer)
Based on information in initialization context normalizer, this function sets
the normalization scheme into configuration context ctx. If NULL is passed to
normalizer, no initialization scheme is set.
For information on the initialization context, refer to the
normalizer module section.
mdn_resconf_setprohibit
mdn_result_t
mdn_resconf_setprohibit(mdn_resconf_t ctx,
mdn_checker_t prohibit_checker)
Based on information in check context prohibit_checker, this function sets the
check scheme for performing prohibited character checking into configuration
context ctx. If NULL is passed to prohibit_checker, no check scheme is set.
For information on the check context, refer to the
checker module section.
mdn_resconf_setunassigned
mdn_result_t
mdn_resconf_setunassigned(mdn_resconf_t ctx,
mdn_checker_t unassigned_checker)
Based on information in check context unassigned_checker, this function sets the
check scheme for performing unassigned codepoint checking into configuration
context ctx. If NULL is passed to unassigned_checker, no check scheme is set.
For information on the check context, refer to the
checker module section.
mdn_resconf_setdelimitermap
mdn_result_t
mdn_resconf_setdelimitermap(mdn_resconf_t ctx,
mdn_delimitermap_t delimiter_mapper)
Based on information in delimiter map context delimiter_mapper, this function
sets a delimiter into configuration context ctx. If NULL is passed to
delimiter_mapper, no delimiter is set.
For information on the delimiter map context, refer to the
delimitermap module section.
mdn_resconf_setmapselector
mdn_result_t
mdn_resconf_setmapselector(mdn_resconf_t ctx,
mdn_mapselector_t map_selector)
Based on information in map selection context map_selector, this function sets
the local mapping scheme into configuration context ctx. If NULL is passed to
map_selector, no selection scheme is set.
For information on the map selection context, refer to the
mapselector module section.
mdn_resconf_setidnconvertername
mdn_result_t
mdn_resconf_setidnconvertername(mdn_resconf_t ctx, const char *name,
int flags)
Sets the IDN encoding into configuration context ctx. If NULL is passed to
idn_converter, no IDN encoding is set.
mdn_resconf_setlocalconvertername
mdn_result_t
mdn_resconf_setlocalconvertername(mdn_resconf_t ctx, const char *name,
int flags)
Sets the local encoding into configuration context ctx. If NULL is passed to
local_converter, an automatically distinguished encoding is set.
mdn_resconf_addallmappernames
mdn_result_t
mdn_resconf_addallmappernames(mdn_resconf_t ctx, const char **names,
int nnames)
Adds all mapping schemes described in names and nnames to configuration context ctx.
mdn_resconf_addallnormalizernames
mdn_result_t
mdn_resconf_addallnormalizernames(mdn_resconf_t ctx, const char **names,
int nnames)
Adds all normalization schemes described in names and nnames to configuration context ctx.
mdn_resconf_addallprohibitnames
mdn_result_t
mdn_resconf_addallprohibitnames(mdn_resconf_t ctx, const char **names,
int nnames)
Adds all prohibited character check schemes described in names and nnames to configuration context ctx.
mdn_resconf_addallunassignednames
mdn_result_t
mdn_resconf_addallunassignednames(mdn_resconf_t ctx, const char **names,
int nnames)
Adds all unassigned codepoint check schemes described in names and nnames to configuration context ctx.
mdn_resconf_addalldelimitermapucs
mdn_result_t
mdn_resconf_addalldelimitermapucs(mdn_resconf_t ctx,
unsigned long *v, int nv);
Adds all delimiters represented in the codepoint array v of length nv into
configuration context ctx. To use a delimiter, always be sure to call
mdn_resconf_fixdelimitermap before using
mdn_res_nameconv to perform delimiter
mapping, and declare that a delimiter will not be subsequently added.
mdn_resconf_fixdelimitermap
mdn_result_t mdn_resconf_fixdelimitermap(mdn_resconf_t ctx)
Declares that delimiters will no longer be added. When
mdn_resconf_addalldelimitermapucs is used to add a delimiter,
mdn_res_nameconv-induced delimiter mapping will not be successful unless this
function is called.
mdn_resconf_allallmapselectornames
mdn_result_t
mdn_resconf_addallmapselectornames(mdn_resconf_t ctx, const char *tld,
const char **names, int nnames)
Adds all local mapping schemes for the top level domain tld described in names and nnames to configuration context ctx.
mdn_resconf_setnameprepversion
mdn_result_t
mdn_resconf_setnameprepversion(mdn_resconf_t ctx,
const char *version)
Sets version into the NAMEPREP version of configuration context ctx.
result module
The result module handles the
mdn_result_t type value returned by each function
in the library and converts the value to the corresponding message code.
This module provides the following API functions.
mdn_result_tostring
char * mdn_result_tostring(mdn_result_t result)
Returns the message character string corresponding to the value result of
mdn_result_t type.
An unknown result code character string is returned for undefined code.
selectiveencode module
The selectiveencode module finds domain names that include non-ASCII characters
in text such as zone master files. Generally speaking it is impossible
to determine which part of the text is the domain name; in actuality, however,
the following rough assumptions are used to implement it approximately.
- Non-ASCII characters appear only in domain names.
Specifically, the following algorithm is used to detect the domain name area.
- Scans the text and finds non-ASCII characters.
- Check characters before and after found non-ASCII characters to determine a range consisting of only the found character and also other non-ASCII characters or characters that can be used for conventional (not internationalized) domain names.
- Returns the found range as the domain name.
This module provides the following API functions.
mdn_selectiveencode_findregion
mdn_result_t
mdn_selectiveencode_findregion(const char *s,
char **startp, char **endp)
Scans s UTF-8 encoded character strings and finds the area in the domain that includes the first appearance of a non-ASCII character, then stores a pointer indicating the beginning of the area at startp and a pointer indicating the end of the area in endp.
One of the following values is returned:
mdn_success,
mdn_notfound.
strhash module
The strhash module implements a hash table that uses a character string as a
key. The hash table is used by other modules in the library such as the
converter module and
normalizer module.
This is a very general hash table
implementation in which registration can be performed but there is no deletion
function because it is not needed with this library.
The size of the hash table increases as the total numer of elements increases.
As shown below, the hash table is expressed in opaque data of mdn_strhash_t type.
typedef struct mdn_strhash *mdn_strhash_t;
This module provides the following API functions.
mdn_strhash_create
mdn_result_t mdn_strhash_create(mdn_strhash_t *hashp)
Creates an empty hash table and stores the handle to the area indicated by
hashp.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_strhash_destroy
void mdn_strhash_destroy(mdn_strhash_t hash)
Deletes the hash table created by
mdn_strhash_create
and releases the allocated memory.
mdn_strhash_put
mdn_result_t
mdn_strhash_put(mdn_strhash_t hash, const char *key,
void *value)
Used to register a key and value set in the hash table hash created by
mdn_strhash_create. Since character strings key are copied, there is no influence
even if the memory indicated by key is released or the contents of the character
strings are changed after this function is called. Contrarily, the contents of
value are not copied, so use care when working with this item. (If you think
carefully about it, it will become obvious that this value is not copied.)
When the same key is used for registration more than once, only the most recently registered key is effective.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn_strhash_get
mdn_result_t
mdn_strhash_get(mdn_strhash_t hash,
const char *key, void **valuep)
Searches for elements that have key in the hash table hash; if a corresponding element is found, the value is stored in valuep.
One of the following values is returned:
mdn_success,
mdn_noentry.
mdn_strhash_exists
int mdn_strhash_exists(mdn_strhash_t hash, const char *key)
Returns 1 if there is an element that has the key in the hash table hash, and returns 0 if no element is found.
ucsmap module
The ucsmap module is designed to register character mapping rules.
This module is packaged as a low-order module for the
filemapper module, and is
not called directly from the application.
This module provides the following API functions.
mdn__ucsmap_create
mdn_result_t mdn__ucsmap_create(mdn_ucsmap_t *ctxp)
Creates a single UCS mapping context. However, at time of creation, no mapping rules are registered to the context.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn__ucsmap_destroy
void mdn__ucsmap_destroy(mdn_ucsmap_t ctx)
Deletes the context created by
mdn_ucsmap_create, and releases the allocated
memory.
mdn__ucsmap_add
void
mdn__ucsmap_add(mdn_ucsmap_t ctx, unsigned long v, unsigned long *map,
size_t maplen)
Registers the mapping rules of Unicode codepoint v to the context created by
mdn__ucsmap_create.
The mapped sequence is specified by map and maplen. Note,
however, that mapping rules must be registered before calling mdn__ucsmap_fix.
mdn_failure is returned if this function is called once mdn__ucsmap_fix has been
called.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_failure.
mdn__ucsmap_fix
void mdn__ucsmap_fix(mdn_ucsmap_t ctx)
Optimizes the arrangement of the data stored in the context. Once this function
is used,
mdn__ucsmap_add cannot be used subsequently to register a mapping rule.
On the other hand, this function must be called in order to perform character
mapping with mdn__ucsmap_map.
mdn__ucsmap_map
mdn_result_t
mdn_ucsmap_map(mdn_ucsmap_t ctx, unsigned long v, unsigned long *to,
size_t tolen, size_t *maplenp);
Stores the mapped sequence into Unicode codepoint v in to. It passes the size of to in tolen, and the actual length of the mapped sequence is stored in maplenp.
To use this function, you must first have called mdn__ucsmap_fix. mdn_failure is
returned if this function is called without having called mdn__ucsmap_fix.
One of the following values is returned:
mdn_success,
mdn_nomapping,
mdn_failure.
ucsset module
The ucsset module is designed to register characters.
This module is packaged as a low-order module for the
filechecker module and
delimitermap module, and is not called directly from the application.
This module provides the following API functions.
mdn__ucsset_create
mdn_result_t mdn__ucsset_create(mdn_ucsset_t *ctxp)
Creates a single UCS configuration context. No characters are registered to a context that has just been created.
One of the following values is returned:
mdn_success,
mdn_nomemory.
mdn__ucsset_destroy
void mdn__ucsset_destroy(mdn_ucsset_t ctx)
Deletes the context created by mdn__ucsset_create, and releases the allocated memory.
mdn__ucsset_add
void mdn__ucsset_add(mdn_ucsset_t ctx, unsigned long v)
Registers the mapping rules of Unicode codepoint v to the context created by
mdn__ucsset_create. Note, however, that the characters must be registered before
calling mdn__ucsset_fix. mdn_failure is returned if this function is called once
mdn__ucsset_fix has been called.
One of the following values is returned:
mdn_success,
mdn_invalid_code,
mdn_nomemory,
mdn_failure.
mdn__ucsset_addrange
void mdn__ucsset_addrange(mdn_ucsset_t ctx, unsigned long from, unsigned long to)
Registers all Unicode codepoints in the context created by
mdn__ucsset_create
from from to to (including both sides). Note, however, that the characters must
be registered before calling
mdn__ucsset_fix. mdn_failure is returned if this
function is called once mdn__ucsset_fix has been called.
One of the following values is returned:
mdn_success,
mdn_invalid_code,
mdn_nomemory,
mdn_failure.
mdn__ucsset_fix
void mdn__ucsset_fix(mdn_ucsset_t ctx)
Optimizes the arrangement of the data stored in the context. Once this function
is used,
mdn__ucsset_add or
mdn__ucsset_addrange cannot be used subsequently to register characters.
On the other hand, this function must be called in order to determine a
character with mdn__ucsset_lookup.
mdn__ucsset_lookup
mdn_result_t mdn__ucsset_lookup(mdn_ucsset_t ctx, unsigned long v, int *found)
Checks if Unicode codepoint v is included in ctx. If it is, the function stores 1 in *found; if not, it stores 0 in *found.
To use this function, you must first have called mdn__ucsset_fix. mdn_failure is
returned if this function is called without having called mdn__ucsset_fix.
One of the following values is returned:
mdn_success,
mdn_nomemory,
mdn_failure.
unicode module
The unicode module obtains various character properties of Unicode described in
UnicodeData.txt. For details of the data described in Unicode.txt and the file
format, refer to
UnicodeData File Format.
Many modules in this library handle Unicode data as UTF-8 encoded character
strings but this module handles Unicode data as unsigned long type data.
Includes UCS-4 values.
The data about character attribute defined by Unicode have some version, and they are deferent each other.
So, to get the data by the specified version, API functions provided by this module can specify an argument as a key to specify a version.
The type of the key is mdn__unicode_version_t type, so defined as the follwoing opaque type.
typedef struct mdn__unicode_ops *mdn__unicode_version_t;
This module provides a mutual conversion function between uppercase and lowercase Unicode characters. This is defined by Unicode Technical Report #21: Case Mappings. Among Unicode characters, a few characters require context information when uppercase is converted to lowercase. This is specified by the following enumeration type data.
typedef enum {
mdn__unicode_context_unknown,
mdn__unicode_context_final,
mdn__unicode_context_nonfinal
} mdn__unicode_context_t;
When the context is FINAL, mdn__unicode_context_final is specified and when it
is NON_FINAL, mdn__unicode_context_nonfinal is specified.
mdn__unicode_context_unknown indicates that the context is unknown (has not yet
been checked). For a detailed discussion of context information, refer to the
above references.
This module provides the following API functions.
mdn__unicode_create
mdn_result_t mdn__unicode_create(const char *version, mdn__unicode_version_t *versionp)
Create the key corresponded the version specified by version,
and set the region versionp points.
In version, for example "3.0.1", the string indicating a version.
If specified NULL, create the key corresponded the latest version supported by this module.
One of the following values is returned:
mdn_success,
mdn_notfound (If not supported the specified version)
mdn__unicode_destroy
void mdn__unicode_destroy(mdn__unicode_version_t version)
Destoroy the key version created by mdn__unicode_create.
mdn__unicode_canonicalclass
int
mdn__unicode_canonicalclass(mdn__unicode_version_t version,
unsigned long c);
By using the character attribute date of the version specified version, Obtains Canonical Combining Class for Unicode character c.
0 is returned for
characters for which Canonical Combining Class is not defined.
However version is the key created by mdn__unicode_create.
mdn__unicode_decompose
mdn_result_t
mdn__unicode_decompose(mdn__unicode_version_t version,
int compat, unsigned long *v, size_t vlen,
unsigned long c, int *decomp_lenp)
Decomposes Unicode characters c in accordance with Character Decomposition Mapping of the version specified by version and writes the result in the area specified by v and
vlen. When the value of compat is true, Compatibility Decomposition is performed
and when false, Canonical Decomposition is performed.
However version is the key created by mdn__unicode_create.
Decompose is performed recursively, i.e. each character resolved in accordance with Character Decomposition Mapping is further decomposed.
One of the following values is returned:
mdn_success,
mdn_notfound,
mdn_nomemory.
mdn__unicode_compose
mdn_result_t
mdn__unicode_compose(mdn__unicode_version_t version,
unsigned long c1, unsigned long c2, unsigned long *compp)
Composes a sequence of the two Unicode characters c1 and c2 per the Character
Decomposition Mapping in the version specified by version and writes the result in the area
specified by compp. Canonical Composition is always peformed.
However version is the key created by mdn__unicode_create.
One of the following values is returned:
mdn_success,
mdn_notfound.
mdn__unicode_iscompositecandidate
int
mdn__unicode_iscompositecandidate(mdn__unicode_version_t version,
unsigned long c)
By using the data of Unicode character attribute of the version specified by version, searches whether there is a Canonical Composition that starts with a Unicode
character c and returns 1 if there is a possibility of its existence and returns
0 if not. This is simply hint information, in that even though 1 is returned,
the composition sometimes does not exist. On the contrary, when 0 is returned,
it definitely does not exist.
However version is the key created by mdn__unicode_create.
As there are only a small number of Unicode characters that can begin Canonical
Composition, this can be used for pre-screening of data in order to decrease the
search overhead of
mdn__unicode_compose.
mdn__unicode_toupper
mdn_result_t
mdn__unicode_toupper(mdn__unicode_version_t version,
unsigned long c, mdn__unicode_context_t ctx,
unsigned long *v, size_t vlen, int *convlenp)
Converts Unicode characters c to uppercase in accordance with the Uppercase
Mapping information in the data of Unicode character attribute of the version specified by version and SpecialCasing.txt, and stores the
result in the area specified by v. vlen is the size of the area that is secured
for v beforehand. The number of characters in the conversion result is returned
to *convlenp. Note that the conversion result may be greater than one character
and that locale-dependent conversion is not performed.
However version is the key created by mdn__unicode_create.
ctx is context information where character c appears. Since most characters do
not require
context information when they are converted, usually
mdn__unicode_context_unknown can be specified. When context information is
necessary, this function returns mdn_context_required as the return value, and
it is possible to call it again after obtaining the context information. To
obtain context information, mdn__unicode_getcontext is used.
If no corresponding uppercase character exists, c is stored in v as is.
One of the following values is returned:
mdn_success,
mdn_context_required,
mdn_buffer_overflow.
mdn__unicode_tolower
mdn_result_t
mdn__unicode_tolower(mdn__unicode_version_t version,
unsigned long c, mdn__unicode_context_t ctx,
unsigned long *v, size_t vlen, int *convlenp)
Converts Unicode character c to lowercase in accordance with Lowercase Mapping
information of the data of Unicode character attribute and SpecialCasing.txt information.
Since the usage method is the same as mdn__unicode_toupper(), which is used to convert to upper case character, refer to that section.
mdn__unicode_getcontext
mdn__unicode_context_t
mdn__unicode_getcontext(mdn__unicode_version_t version,
unsigned long c)
By using the data of Unicode character attribute of the version specified by version, returns context information used for conversion of uppercase/lowercase
characters. To obtain context information, first the character following the
uppercase/lowercase character conversion target character is obtained and this
function is called. If the return value is mdn__unicode_context_final or
mdn__unicode_context_nonfinal, that context information is the context
information to obtain. If mdn__unicode_context_unknown is returned, the next
character is obtained and the function is called. In this way, processing
continues until either the value of mdn__unicode_context_final or
mdn__unicode_context_nonfinal is obtained. When processing reaches the end of
the character string, mdn__unicode_context_final becomes the context.
Specifically, this function does the following. Refers "General Category"
properties of Unicode character c and if it is "Lu", "Ll" or "Lt"
mdn__unicode_context_nonfinal is returned, if it is "Mn"
mdn__unicode_context_unknown is returned, and if it is other than the above,
mdn__unicode_context_final is returned.
unormalize module
The unormalize module performs the standard normalization defined by Unicode.
Normalization of Unicode is defined in
Unicode Technical Report #15: Unicode Normalization Forms. This module implements the four normalization forms
mentioned in this document.
The concrete data as using normalization are deferent a little bit each other.
Then, as same as the one of unicode module, API functions provided by this module can specify an argument as a key to specify a version.
To create and destoroy the key, use mdn__unicode_create and
mdn__unicode_destroy of unicode module.
This module provides the following API functions.
mdn__unormalize_formc
mdn_result_t
mdn__unormalize_formc(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
Applies Unicode Normalization Form C normalization which is the version specified by version to a UTF-8 encoded from
character string and writes the result in the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_buffer_overflow,
mdn_nomemory.
mdn__unormalize_formd
mdn_result_t
mdn__unormalize_formd(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
Applies Unicode Normalization Form D normalization which is the version specified by version to a UTF-8 encoded from
character string and writes the result in the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_buffer_overflow,
mdn_nomemory.
mdn__unormalize_formkc
mdn_result_t
mdn__unormalize_formkc(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
Applies Unicode Normalization Form KC normalization which is the version specified by version to a UTF-8 encoded from
character string and writes the result in the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_buffer_overflow,
mdn_nomemory.
mdn__unormalize_formkd
mdn_result_t
mdn__unormalize_formkd(mdn__unicode_version_t version,
const char *from, char *to, size_t tolen)
Applies Unicode Normalization Form KC normalization which is the version specified by version to a UTF-8 encoded from
character string and writes the result in the area specified by to and tolen.
One of the following values is returned:
mdn_success,
mdn_invalid_encoding,
mdn_buffer_overflow,
mdn_nomemory.
utf5 module
The utf5 module performs basic processing for the proposed
UTF-5 domain name
encoding system. However, because this encoding is already outdated encoding, be careful to use.
This module provides the following API functions.
mdn_utf5_getwc
int
mdn_utf5_getwc(const char *s, size_t len,
unsigned long *vp)
Extracts the leading character of length len byte UTF-5 encoded character strings s, converts it to UCS-4 and stores it in the area specified by vp and also returns the number of bytes in the (UTF-5 encoded) character strintg. 0 is returned if len is too short and ends in the middle of a character or the encoding is invalid.
mdn_utf5_putwc
int mdn_utf5_putwc(char *s, size_t len, unsigned long v)
Converts UCS-4 characters v to UTF-5 encoding, writes them in the area specified by s and len and returns the number of bytes written. 0 is returned if len is too short to write.
The written UTF-5 character string is not terminated with a NULL character.
utf6 module
The utf6 module converts between the proposed
UTF-6 encoding multilingual domain name encoding method and UTF-8. However, because this encoding is already outdated encoding, be careful to use.
This module is packaged as a low-order module for the converter module, and is not called directly from the application. It is called indirectly when conversion to or from UTF-6 encoding is requested of the converter module.
This module provides the following API functions.
mdn__utf6_open
mdn_result_t
mdn__utf6_open(mdn_converter_t ctx, mdn_converter_dir_t dir,
void **privdata)
Opens conversion to or from UTF-6 encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__utf6_close
mdn_result_t
mdn__utf6_close(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir)
Closes conversion to or from UTF-6 encoding. Actually, this does not do anything.
Always returns mdn_success.
mdn__utf6_convert
mdn_result_t
mdn__utf6_convert(mdn_converter_t ctx, void *privdata,
mdn_converter_dir_t dir, const char *from, char *to,
size_t tolen)
This performs bi-directional conversion between UTF-6 encoded character strings
and UTF-8 encoded character strings. It converts the input character string
from, and writes the result to the area specified by to and tolen. If dir is
mdn_converter_l2u, it converts from UTF-6 encoding to UTF-8 encoding, if dir is
mdn_converter_u2l, it converts from UTF-8 encoding to UTF-6 encoding.
One of the following values is returned:
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding,
mdn_nomemory.
utf8 module
The utf8 module performs the basic processing of UTF-8 encoded character
strings.
This module provides the following API functions.
mdn_utf8_mblen
int mdn_utf8_mblen(const char *s)
Returns the length (number of bytes) of the leading character in the UTF-8 character string s. 0 is returned if the leading byte indicated by s is not valid for UTF-8.
This function returns the length by checking the leading byte of s; there is therefore a possibility of invalid byte in the 2nd and later byte. In particular, NULL bytes may exist in the middle, so you have to be careful when it is not certain that s is a valid UTF-8 character string.
mdn_utf8_getmb
int mdn_utf8_getmb(const char *s, size_t len, char *buf)
Copies the leading character of s UTF-8 character strings of length len and returns the number of copied bytes. 0 is returned if len is too short to write or the leading character indicated by s is not valid for UTF-8.
buf must be large enough to hold any UTF-8 encoding, i.e. it must be 6 bytes or larger.
The written UTF-8 character string is not terminated with a NULL character.
mdn_utf8_getwc
int
mdn_utf8_getwc(const char *s, size_t len,
unsigned long *vp)
This is almost the same as mdn_utf8_getmb with the difference being that characters
extracted from s are converted to UCS-4 and stored in the area indicated by vp.
mdn_utf8_putwc
int mdn_utf8_putwc(char *s, size_t len, unsigned long v)
Converts UCS-4 character v to UTF-8 encoding, writes it in the area specified by s and len and returns the number of written bytes. 0 is returned when the value of v is invalid or len is too short.
The written UTF-8 character string is not terminated with a NULL character.
mdn_utf8_isvalidstring
int mdn_utf8_isvalidstring(const char *s)
Checks whether the character string s terminated with a NULL character is valid UTF-8 encoding and returns 1 if so and 0 if not.
mdn_utf8_findfirstbyte
char *
mdn_utf8_findfirstbyte(const char *s,
const char *known_top)
In the character string, known_top checks the leading byte of UTF-8 characters
including the byte indicated by s and returns it. NULL is returned if there are
any incorrectly encoded UTF-8 characters or no leading byte between
known_top and s.
util module
The util module provides utility type functions used by other modules. The only function currently provided is a character string collation function that does
not differentiate between uppercase and lowercase characters.
This module provides the following API functions.
mdn_util_casematch
int mdn_util_casematch(const char *s1, const char *s2, size_t n)
Compares the maximum n bytes from the beginning of character strings s1 and s2
and determines whether they are identical. Uppercase and lowercase ASCII
characters (i.e. A to Z and a to z) are assumed to be the same. 1 is returned if
they are found to be identical and 0 is returned if not. With the exception of
the return value specifications, this function provides almost the same features
as strcasencmp, which is provided in many systems.
mdn_util_domainspan
const char * mdn_util_domainspan(const char *s, const char *end)
Obtains the range of characters that can be used as ASCII domain names. Checking starts with s and ends with end (not including characters that are not indicated by end) to find whether each character is an ASCII alphanumeric or hyphen. If another character is found, the location of the first appearance of such character is returned. When all characters are found alphanumerics or hyphens, end is returned.
mdn_util_validstd13
int mdn_util_validstd13(const char *s, const char *end)
Checks whether the (part) character string indicated by s and end is the correct format as the ASCII domain name label (each part delimited by period). However, end indicates the character following the last character. Also, when end is NULL, checking target is from s to NUL character.
Character strings that satisfy the following requirements are determined to be the correct format.
- Composed of only ASCII alphanumerics and hyphens.
- The first and last characters are not both hyphens.
When the format is correct, 1 is returned and if not, 0 is returned.
mdn_util_utf8toutf16
mdn_result_t
mdn_util_utf8toutf16(const char *utf8, size_t fromlen,
unsigned short *utf16, size_t tolen, size_t *reslenp)
Converts character string utf8 in UTF-8 format of length fromlen to UTF-16 format (16 bit integer arrangement) and stores the result in utf16. tolen is the field size (number of characters) indicated by utf16. The length of the character string after conversion is stored in *reslenp.
The return value is mdn_success, mdn_buffer_overflow, or mdn_invalid_encoding.
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding.
mdn_util_utf16toutf8
mdn_result_t
mdn_util_utf16toutf8(const unsigned short *utf16, size_t fromlen,
char *utf8, size_t tolen, size_t *reslenp)
Converts the data utf8 (16 bit integer arrangement) in UTF-16 format of length fromlen to the character string in UTF-8 format and stores the result in utf8. tolen is the field size (number of bytes) indicated by utf8. The length of the character string after conversion is stored in *reslenp.
The return value is mdn_success, mdn_buffer_overflow, or mdn_invalid_encoding.
mdn_success,
mdn_buffer_overflow,
mdn_invalid_encoding.
version module
The version module provides MDN library version functions.
This module provides the following API functions.
mdn_version_getstring
const char * mdn_version_getstring(void);
Returns a character string representing the MDN library version number.
